OpenTelemetry for LLM Applications: A Practical Guide with LaunchDarkly and Langfuse
OpenTelemetry for LLM Applications: A Practical Guide with LaunchDarkly and Langfuse
Published February 27, 2026

LLM applications have a telemetry problem. Unlike traditional software where you can trace a bug to a specific line of code or a failed API call, LLM failures are a bit more nuanced. A response that’s slightly off, a prompt that worked yesterday but not today, or a model swap can quietly degrade your user experience. OpenTelemetry gives you a structured way to pull back the curtain by capturing token usage, model metadata, latency, and agent responses so you truly know what’s happening inside your application.
This tutorial walks you through instrumenting a real LLM application with OTel spans, capturing the right attributes, and fanning out those traces simultaneously to Langfuse and LaunchDarkly’s Guarded Releases. Both are LLM observability tools, but they give you different lenses on the same trace data. Langfuse is purpose-built for prompt debugging and cost analysis — surfacing prompt content, completions, and per-agent token usage.
LaunchDarkly connects that same trace data to the specific model variant that was active during a request, giving you flag-correlated observability with automated rollback if a variant starts degrading your users’ experience. One OTel collector, two complementary views, no custom integrations required.
The WorkLunch App
In order to see the full process of instrumenting an LLM application, I added a new feature in an app called WorkLunch where users were able to create/join office communities and swap lunches based on preference. Now they’re also able to improve the description field of their lunch post to make it more appealing to potential swappers and receive recommendations for compatible swaps.
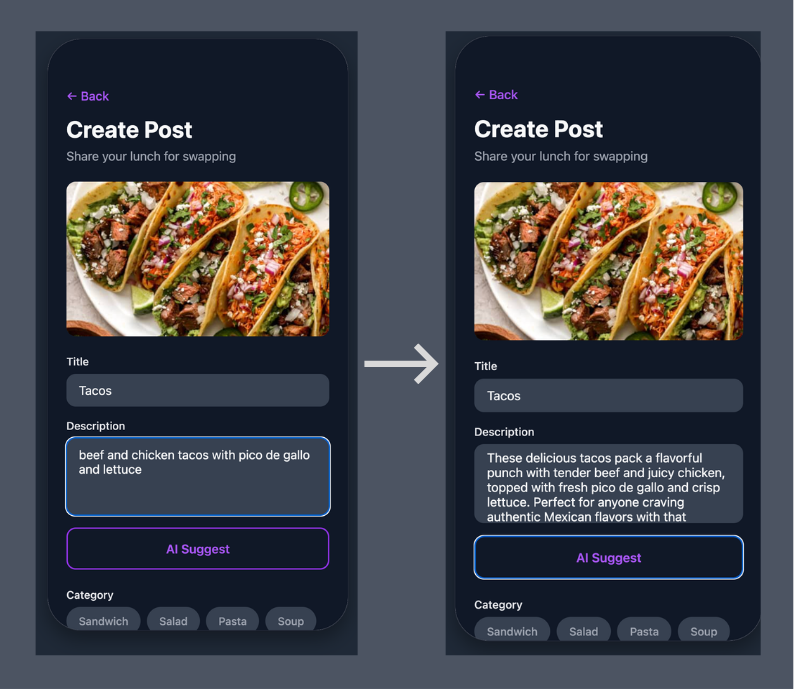
So in the initial description you may write, “Grilled cheese sandwich”, then click the AI Suggest button. The app replaces it with, “Golden, buttery grilled cheese with perfectly melted cheese sandwiched between crispy white bread. This comfort food classic is grilled to perfection with a satisfying crunch on the outside and gooey, cheesy goodness on the inside. Simple, delicious, and guaranteed to hit the spot!”
Now which lunch post are you more than likely to click on?
This subtle addition takes the app from a fun, simple lunch swap experience to a viable LLM application that still requires the same visibility and observability of traditional systems. OpenTelemetry allows you to extract the necessary data like token count, model name, agent responses, etc in order to properly debug system failures.
Multi-Agent Architecture
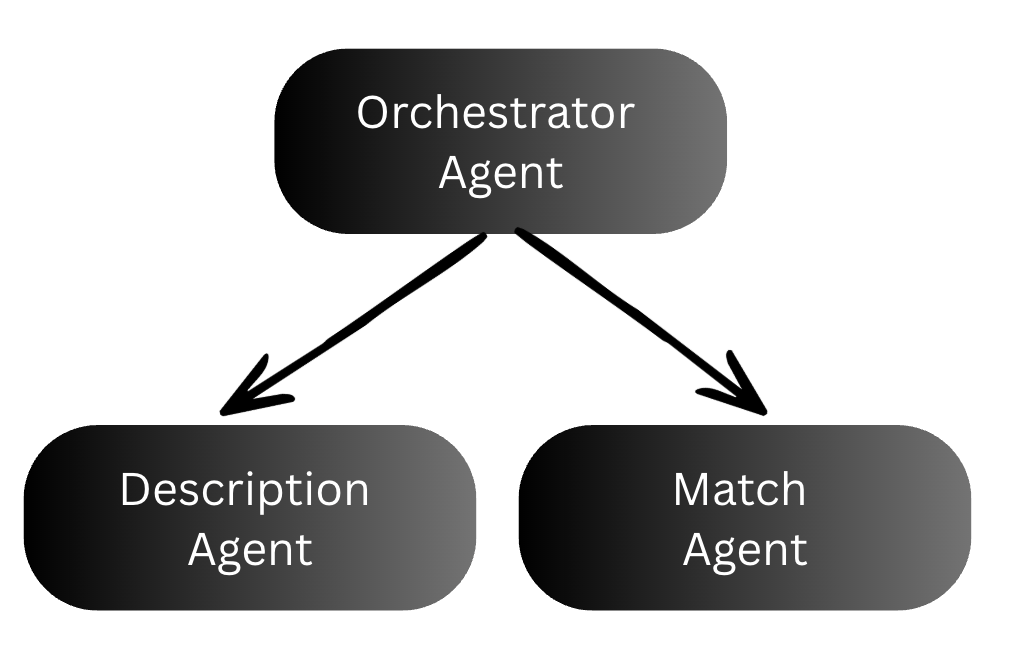
The WorkLunch backend uses 3 agents to rewrite the lunch post description and find good lunch swaps.
- The orchestrator coordinates the other two agents. It receives the user’s request and the model type, calls the description agent first, then passes the generated description into the match agent. It acts as the parent span that ties the whole chain together.
- The description agent takes the user’s sparse lunch post input and calls Claude to generate an appealing 2-3 sentence description.
- The match agent takes the user’s lunch post (including the description just generated) plus a list of other active posts in the community, and uses AI to suggest 2-3 posts that would make good swaps.
These features are controlled by two feature flags, one for enabling the AI suggest feature and the other to control which model version the app uses. Every layer gets its own OTel span, creating a trace tree that shows the full request lifecycle.
Prerequisites
Before you start, you’ll need the following installed locally and accounts set up with the services below.
- Docker Desktop
- Node.js / Npm
- An Anthropic account (or openai)
- A LaunchDarkly account (sdk key and access token)
- A Langfuse account (public and secret key)
- A Supabase account (database configuration)
Environment variables
Once you’re all setup, clone the WorkLunch repo. Copy the example .env file and fill in your values:
Your .env should contain:
Supabase setup
- Create a new Supabase project and grab your Project URL and Anon key from Dashboard → Settings → API
- Run the migration files in
supabase/migrations/to create the database schema. Execute them in order in the Supabase Dashboard → SQL Editor:
Be sure to run each file in order as later migrations depend on tables and policies from earlier ones.
LaunchDarkly setup
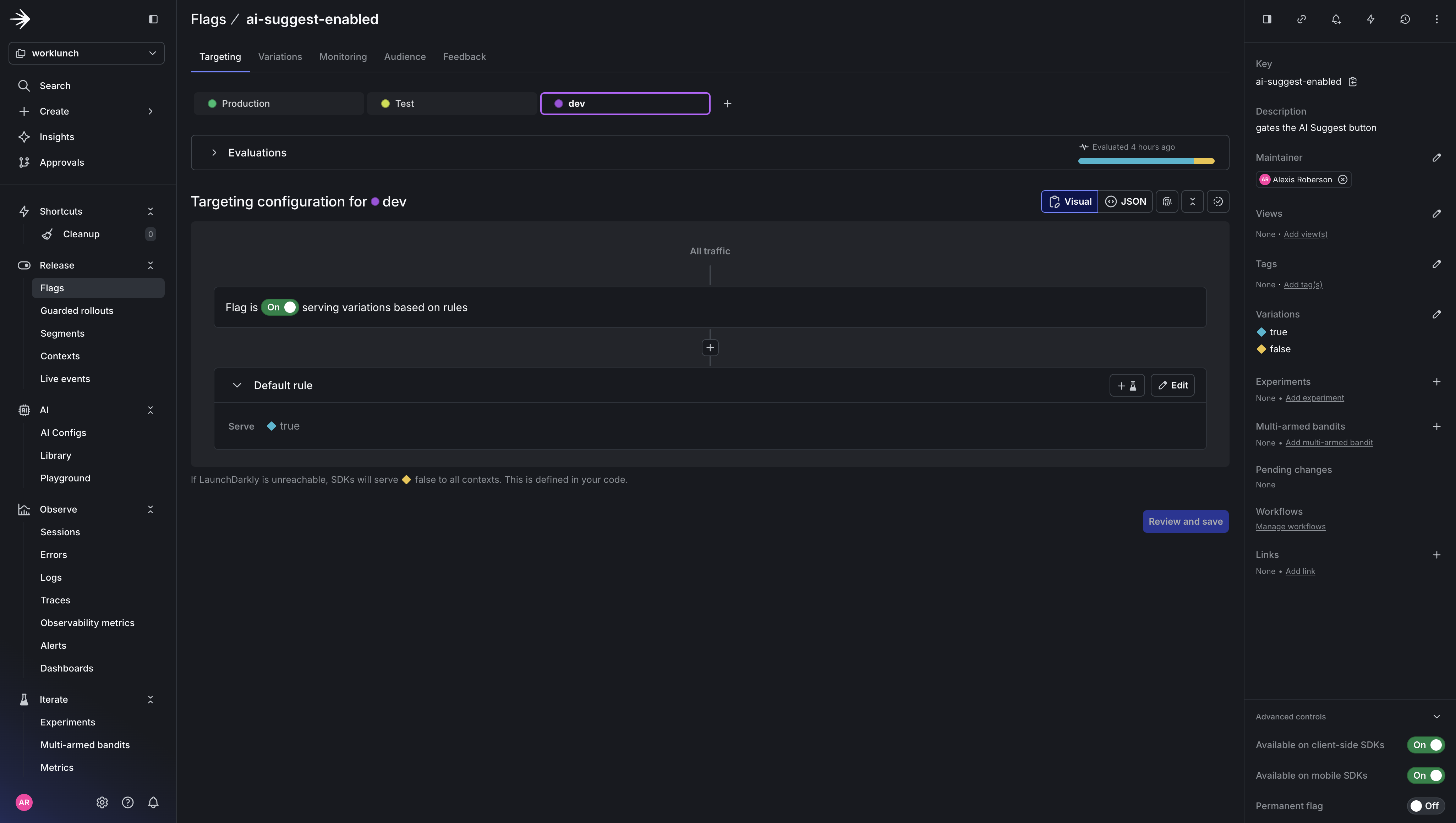
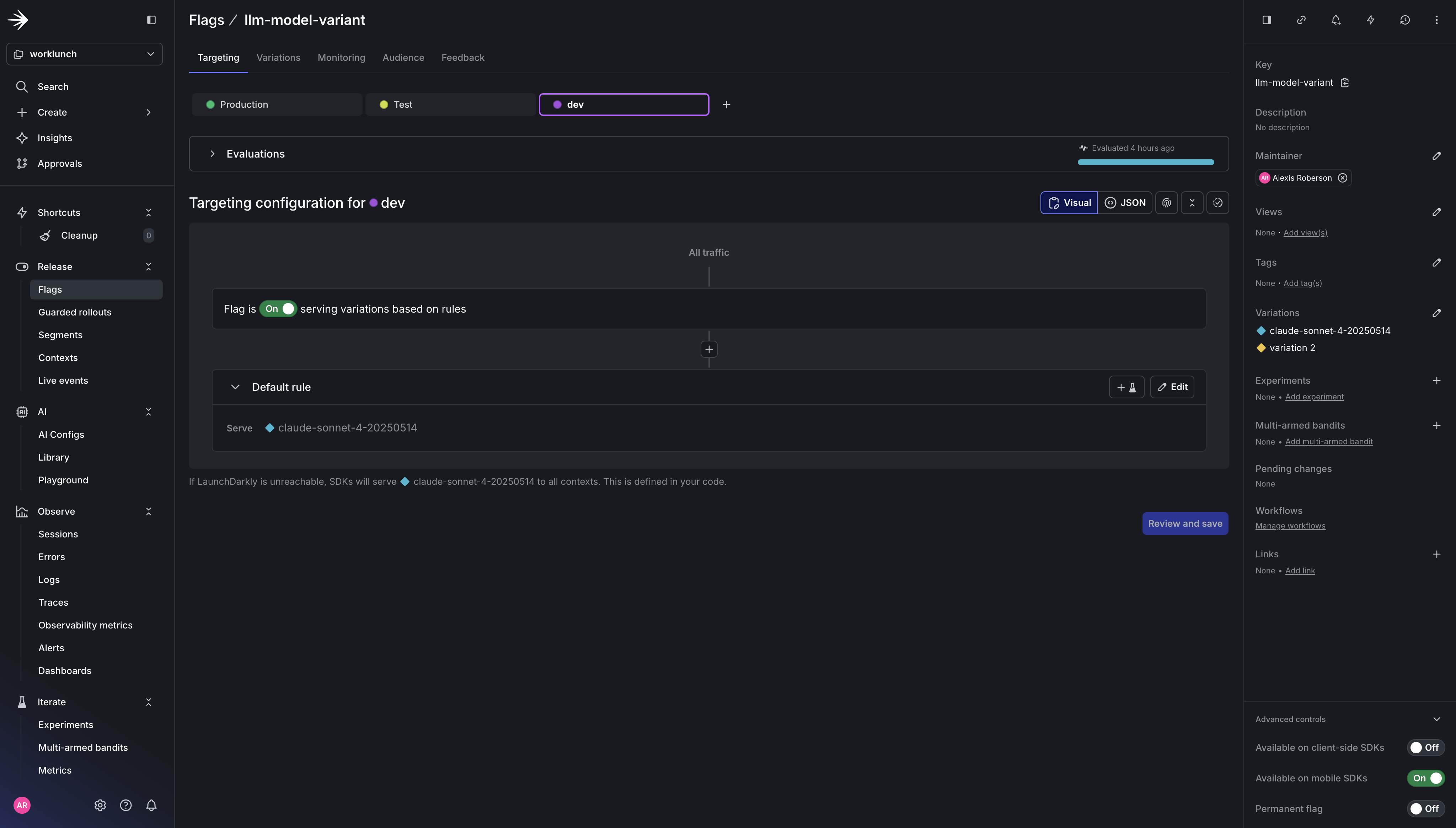
Create two feature flags in your new LaunchDarkly worklunch project:
ai-suggest-enabled— Boolean flag, client-side. Gates visibility of the AI Suggest button in the frontend. Set it totruefor users you want to test with.llm-model-variant— String flag, server-side. Controls which Claude model the backend uses. Set the default value toclaude-sonnet-4-20250514. Add a variation forclaude-haiku-4-5-20251001if you want to experiment with a faster/cheaper model.
Langfuse setup
- Create a new project in Langfuse (note whether your project URL starts with
us.cloud.langfuse.comorcloud.langfuse.com— this determines your region) - Go to Project Settings → API Keys and create a new key pair
- Generate your Base64 auth header and place it inside your .env file:
Quick Start
Once your .env is configured:
Verify traces are flowing by checking the collector logs:
You should see spans with gen_ai.* attributes and feature_flag events printed by the debug exporter.
Now, let’s take a look at how each agent is instrumented to send spans to LaunchDarkly.
Step 1: Instrument your LLM application
Initialize the Tracer and Application
The FastAPI app sets up OTel, LaunchDarkly, CORS, and auto-instrumentation in a single lifespan handler:
The Route: Flag evaluation + feature flag span event
The FastAPI route is where the LaunchDarkly flag gets evaluated. The feature_flag span event on this span is what LaunchDarkly’s observability layer looks for when correlating traces with flag evaluations.
The Orchestrator: Parent span for the agent chain
The orchestrator creates a parent span and calls each sub-agent sequentially. Because the sub-agent spans are created while the orchestrator span is active, OTel automatically nests them as children.
The Description Agent: LLM Call with genAI semantic conventions
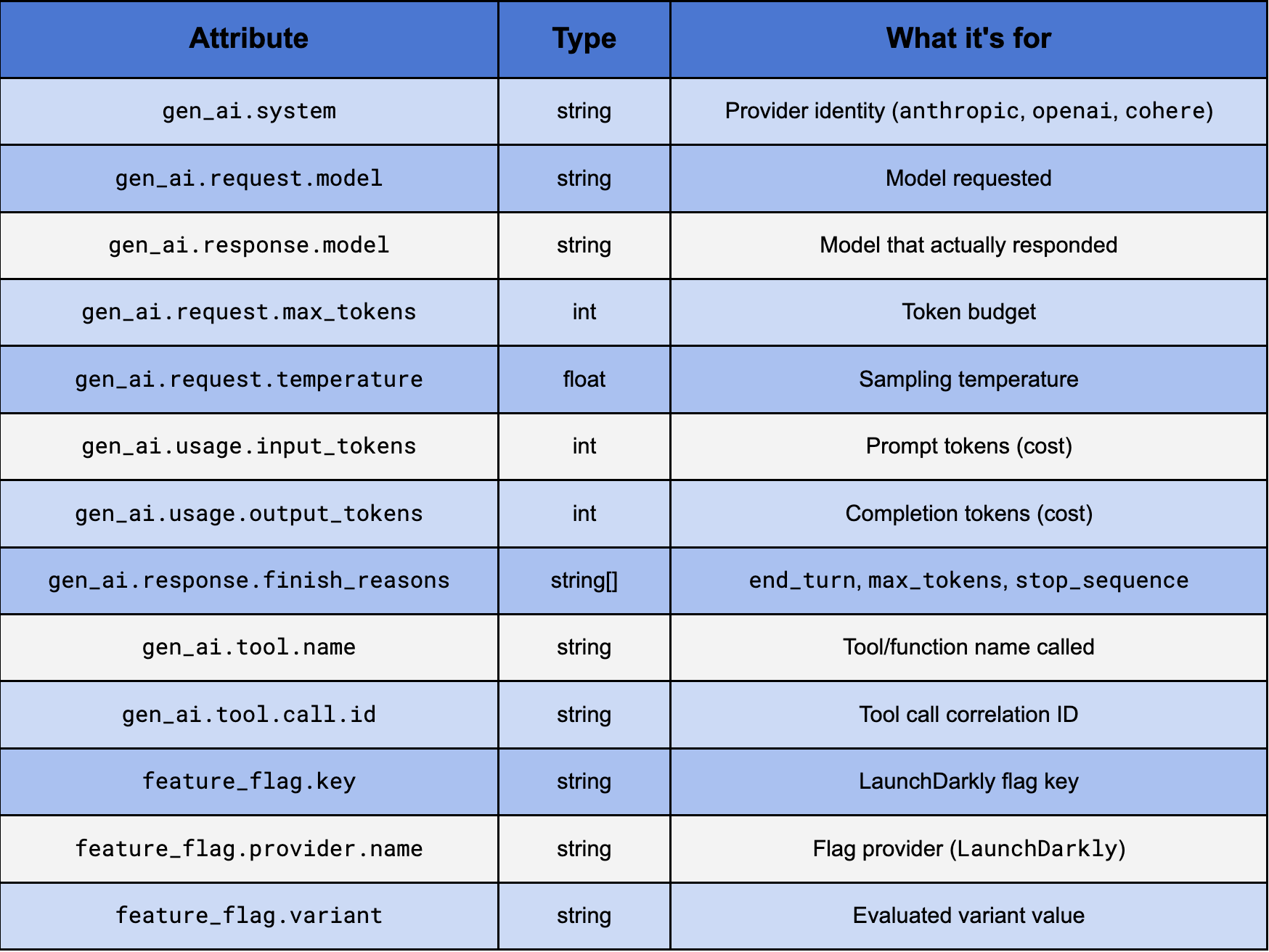
This is where the OTel GenAI Semantic Conventions come in. The conventions define a standard schema for LLM spans — gen_ai.system, gen_ai.request.model, gen_ai.usage.*, and prompt/completion content as span events.
The Match Agent: Structured JSON output from an LLM
The match agent follows the same GenAI span pattern but with different parameters (lower temperature for more deterministic output, higher token budget for JSON) and post-processing to parse structured JSON from the LLM response.
For each of these agents, Langfuse receives the full trace including prompt/completion content for debugging. LaunchDarkly receives the same trace and correlates the feature_flag event with the HTTP span for experimentation metrics.
Step 2: Configure the OTel collector
This is where the fan-out happens. The collector receives traces over OpenTelemetry Protocol (OTLP) and exports them to both backends simultaneously. Two pipelines from the same receiver is the key: you configure one receivers block and reference it in multiple pipelines — no duplication of ingestion, no changes needed in application code.
otel-collector-config.yaml
Now if we rerun our application, we should see LaunchDarkly Traces capturing the Otel spans.
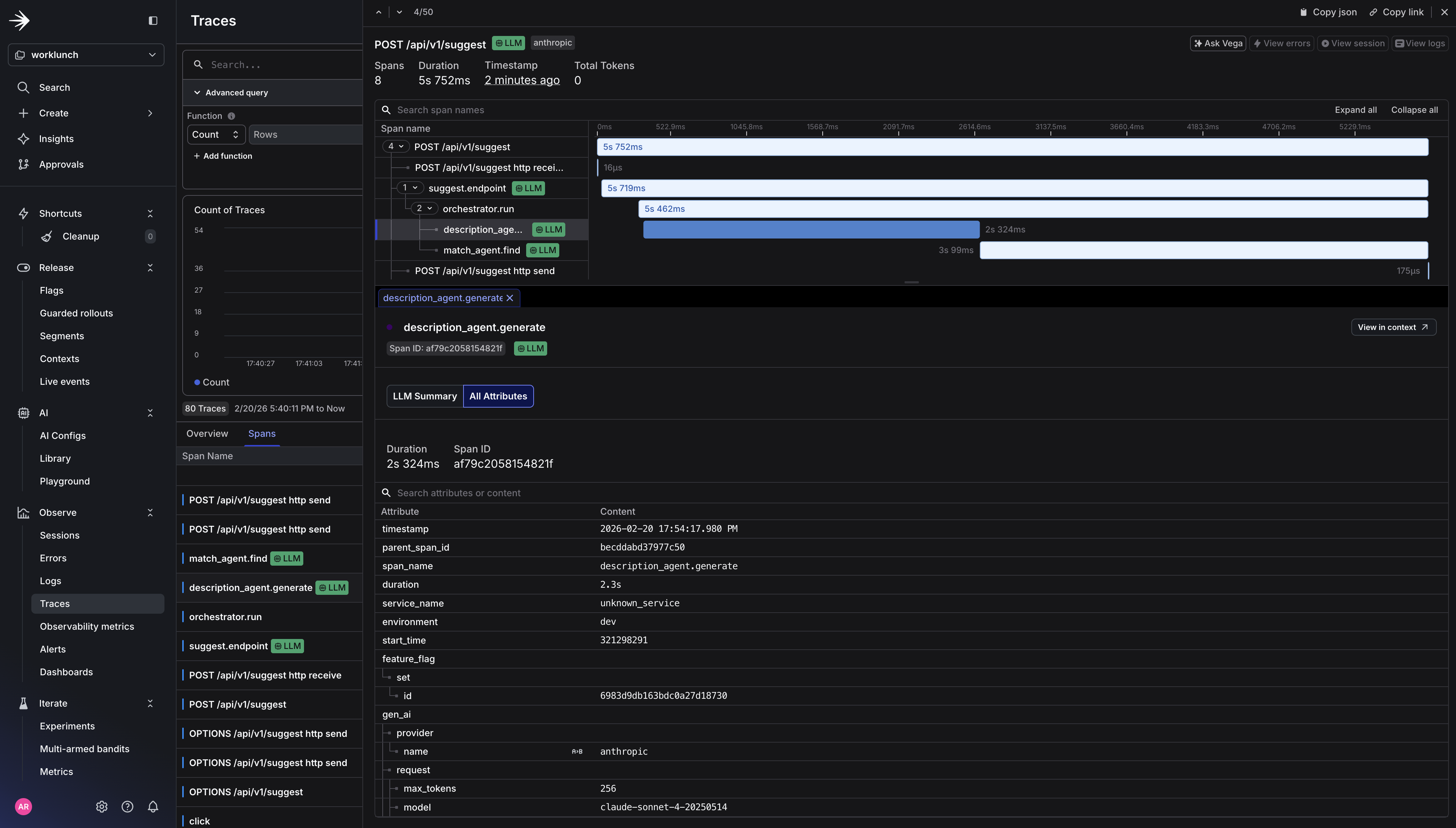
How LaunchDarkly processes OTel traces
LaunchDarkly receives traces for logging and converts OTel span data into events for use with Experimentation and Guarded Rollouts. The process works like this:
- Your application emits a span that covers an HTTP request (or LLM call). This span carries standard HTTP attributes:
http.response.status_code,http.route, latency derived from span duration. - On that same span (or a parent span in the same trace), you’ve emitted a
feature_flagspan event withfeature_flag.keyandfeature_flag.variant. - LaunchDarkly’s collector ingests the trace and looks for HTTP spans that overlap with spans containing at least one
feature_flagevent. When it finds a match, it produces a metric event associating the flag variant with the observed latency and error rate (5xx status codes). - Those metric events flow into Experimentation, where they become the outcome metrics for your flag-controlled A/B test — for example, comparing
claude-sonnet-4-20250514vsclaude-haiku-4-5-20251001on p95 latency and error rate without writing a single line of custom metric instrumentation.
Every span in the agent chain is nested under a single trace. The collector fans out that trace to both backends simultaneously. Langfuse gets the full LLM details for prompt debugging and cost analysis. LaunchDarkly gets the flag-correlated signal it needs for automated rollout decisions.
Key attributes from gen_ai trace spans
Step 3: Trigger a guarded rollout
With traces flowing into LaunchDarkly and span events carrying your flag evaluations, you can now configure a Guarded Rollout that automatically rolls back the AI Suggest feature if token costs spike or response truncation increases as you increase the percentage of users who see it.
In the LaunchDarkly UI, navigate to your flag (ai-suggest-enabled), under Default rule click Edit and select Guarded Rollout.
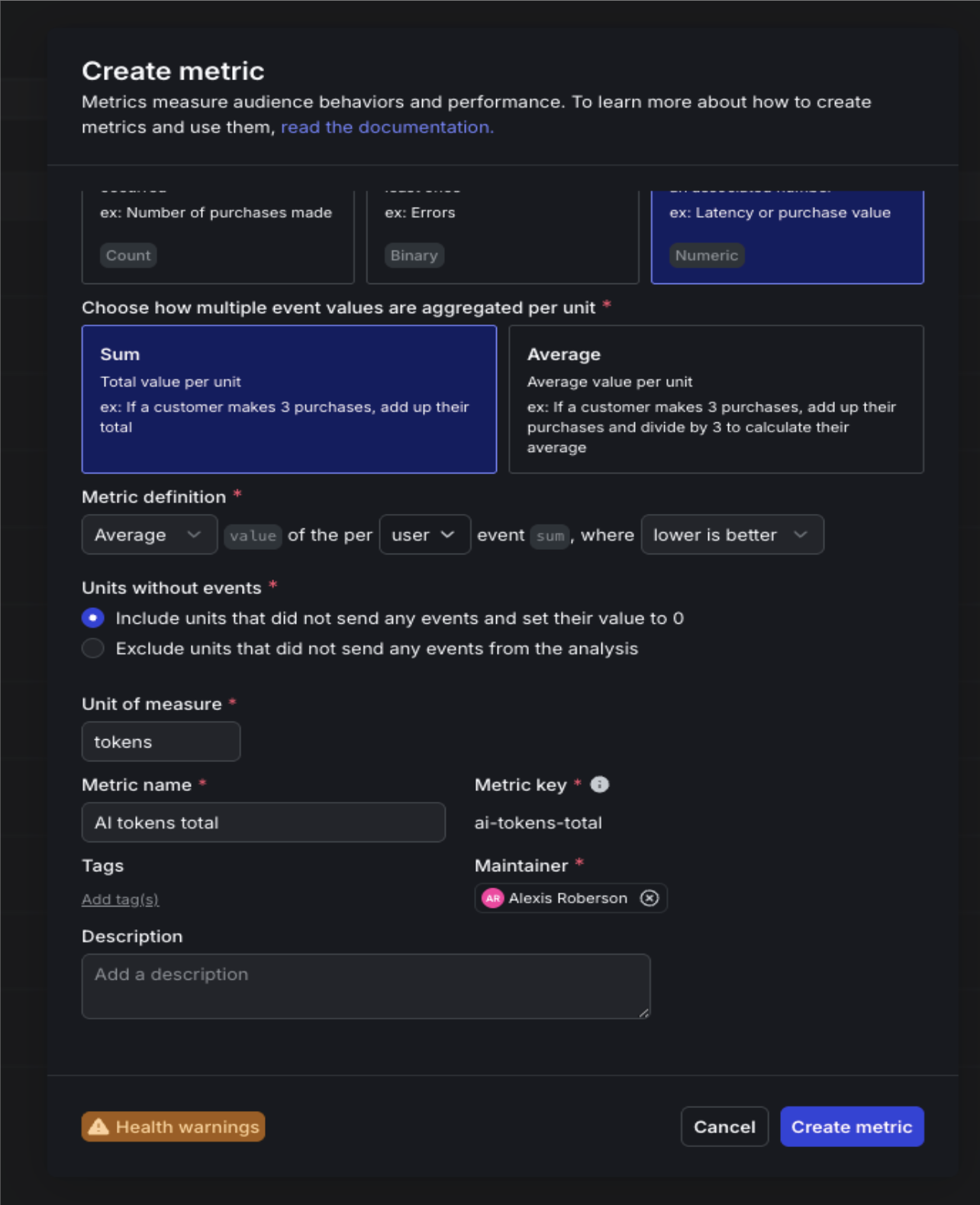
You’ll need to create two new custom metrics to attach to the guarded rollout. The first will is the AI tokens total rollout metric. This will measure cost-per-request as a gate for releasing the feature to a wider audience and alert if average tokens per request exceeds your baseline by more than 25%. And the second is AI completion truncated error metric, which will catch prompt truncation before users notice degraded output quality. This metric will halt the rollout if the rate climbs above your control baseline.
For ai.tokens.total:
- Event kind: Custom
- Event key:
ai.tokens.total - What do you want to measure?: Sum (Numeric) — you’re passing the actual token count as the magnitude
- Metric name: AI tokens total
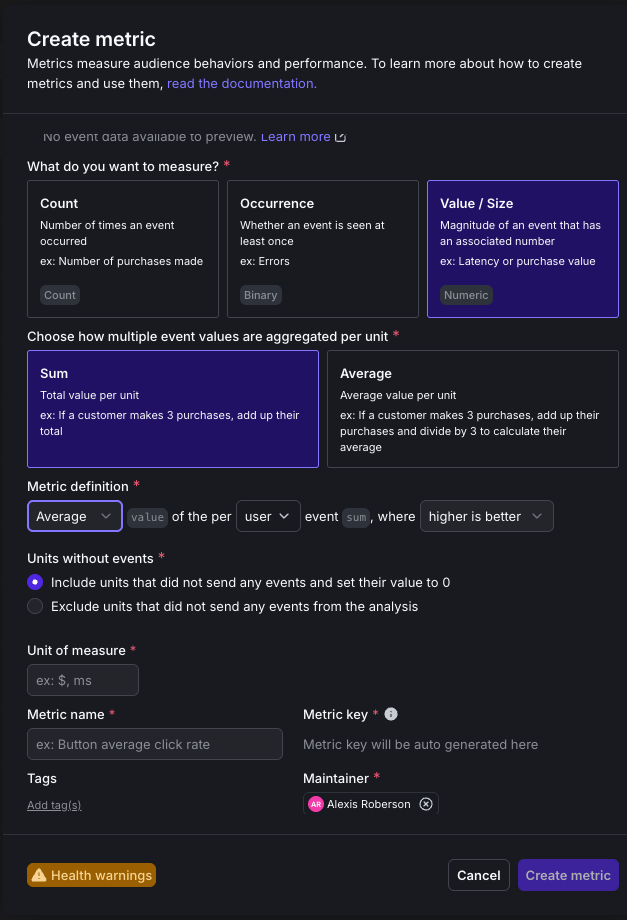
For ai.completion.truncated:
- Event kind: Custom
- Event key:
ai.completion.truncated - What do you want to measure?: Count distinct units (Percent) — you’re tracking whether truncation happened at least once, not how many times
- Metric name: AI completion truncated
Select the two newly created metrics.
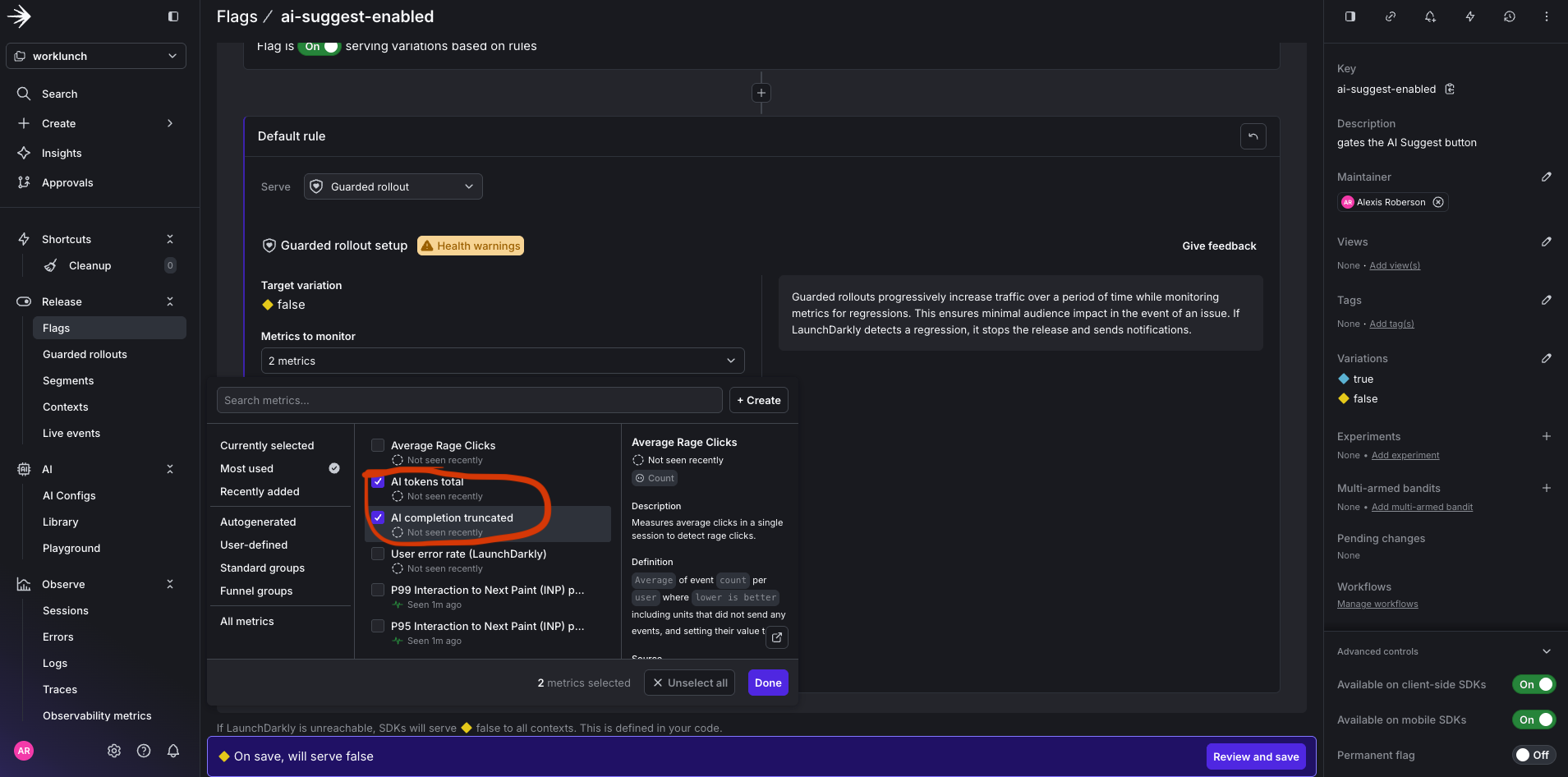
Set the threshold to 25 percent for 1 week.
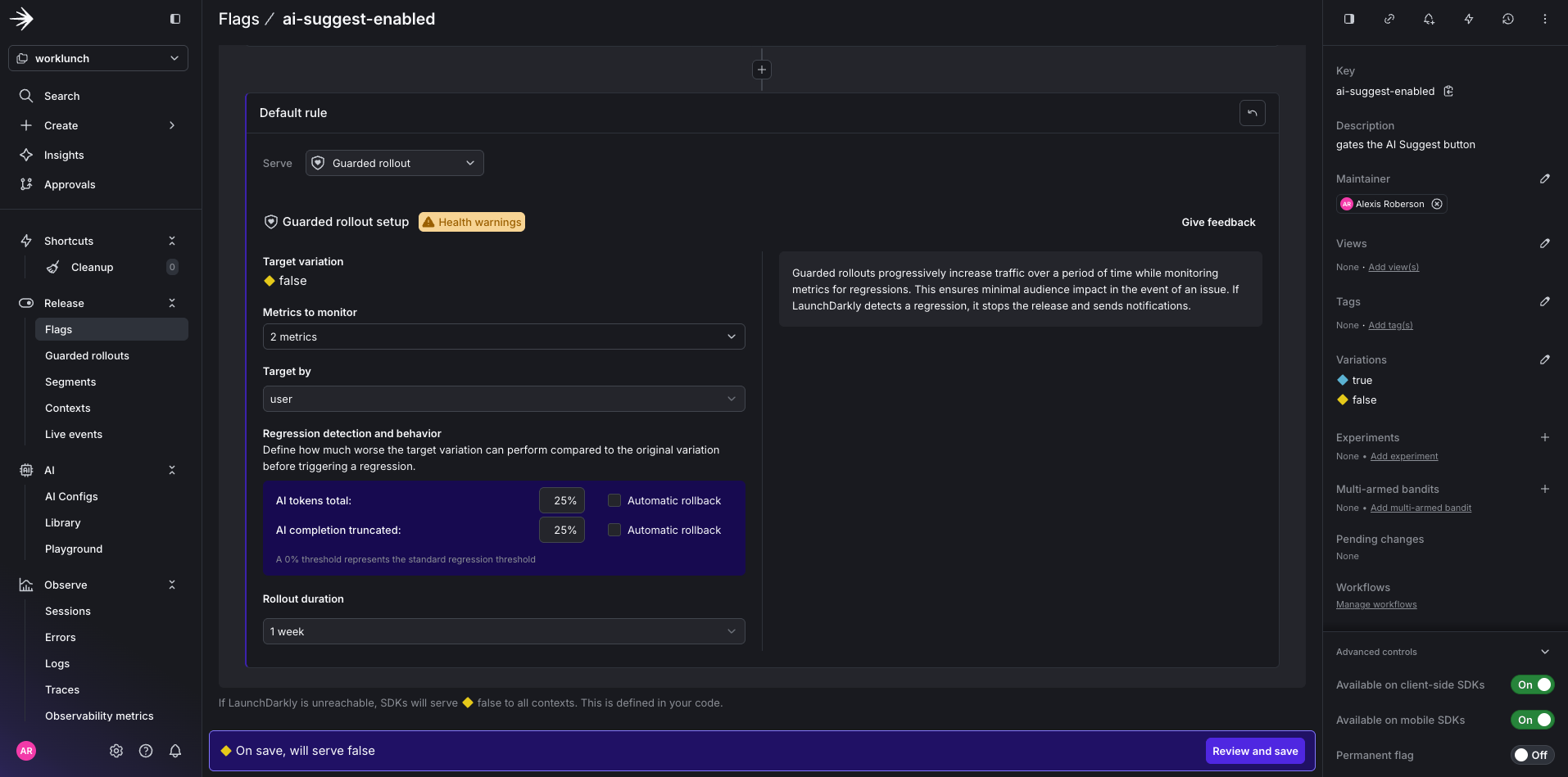
Click Save.
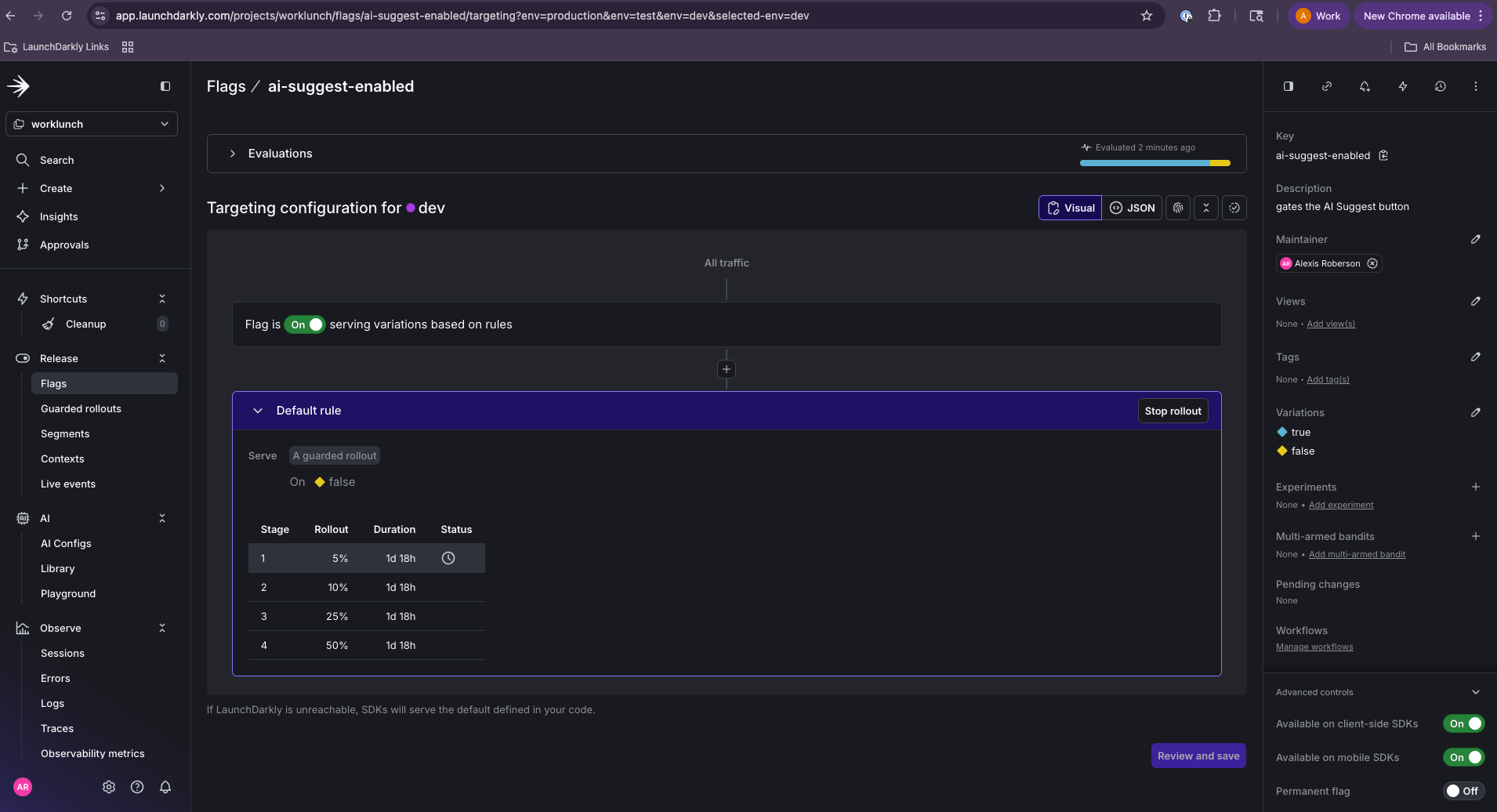
LaunchDarkly will now monitor both metrics against the ai-suggest-enabled flag and trigger an automatic rollback if either threshold is breached.
What You’ve Built
At this point you have a fully instrumented LLM application where every layer of the stack tells a story. The FastAPI route evaluates a LaunchDarkly flag and stamps the result onto the trace. The orchestrator creates a parent span that ties the entire agent chain together. Each agent makes a Claude API call and records exactly what was sent, what came back, and how many tokens it cost. The OTel Collector fans all of that out to two backends simultaneously without a single line of application code changing between them.
Langfuse gives you the LLM-specific view: prompt content, completions, token usage, and latency per agent so you can debug why a description came out wrong or whether the match agent is consistently burning more tokens than expected. LaunchDarkly gives you the experimentation view: which model variant was active during a given request, how latency and error rates compare between claude-sonnet-4-20250514 and claude-haiku, and the automated safety net to roll back if a new variant starts degrading your users’ experience. Both tools are consuming the same trace. Neither required a custom integration.
Conclusion
LLM applications fail in ways that traditional monitoring wasn’t designed to catch. OpenTelemetry gives you the standard schema to do that, and the collector architecture gives you the flexibility to route that signal wherever it’s most useful.
If you’re building anything with LLMs in production, start here. Instrument at the agent level, follow the GenAI semantic conventions, and build your observability pipeline before you need it.
The full source code for the WorkLunch app is available in this GitHub repository. Clone it, swap in your API keys, and you’ll have a working multi-agent trace pipeline running locally in under ten minutes.