How to Set Up Your Production AWS MSK Kafka Cluster
Published February 15, 2023

Looking to set up your own Kafka cluster? AWS MSK is a great choice for a managed Kafka solution, but setting it up correctly can be tricky. We’ll go step-by-step through what you need to do.
Setup Networking
Depending on how you will be connecting to the cluster, you’ll need to configure the networking settings accordingly. If you are only connecting to Kafka from inside your private VPC, then private networking is typically sufficient. On the other hand, if you’re planning to connect to the cluster from the internet (ie. if you were using the Kafka cluster as a development instance from your local machine), you’ll need to set up public access. You will also need public access if you plan to monitor your cluster from a tool hosted on the internet, like with provectuslabs.
Private Access
Setting up a private AWS MSK cluster is the default. Visit your region of the AWS MSK UI, click Create Cluster and then select Custom Create. The default settings will prefer a serverless cluster, but you may want to switch to a provisioned one. Configure your instance size per our sizing guide below. When you visit the networking page, you’ll need to choose or create a private VPC and set the subnets. If you chose to deploy the cluster in 2 availability zones on the first page, then you’ll only need 2 subnets. The number of availability zones your cluster is deployed to will dictate the minimum size of the cluster but also its reliability. If you intend to have a production workload, use a 3-AZ configuration.
Public Access
After picking your public VPC and public subnets, you’ll see a note about Public Access being off. Public Access can only be turned on after the configuration of the cluster, but it requires some things to be configured a certain way during this initial setup. The AWS docs describe the requirements here. Pay attention to the original setup flow as these settings cannot be changed after cluster creation. In short, they are:
Network
- The VPC and all Subnets must be public.
Security
- Unauthenticated access must be turned off, and at least one secured access method must be on of SASL/IAM, SASL/SCRAM, or mTLS. You’ll likely want to use SASL/SCRAM. You’ll need to create a username an password, enroll them in AWS Secrets Manager, and configure Kafka to use that.
- Encryption within the cluster must be turned on.
- Plaintext traffic between brokers and clients must be off
- Setup ACLs with configuration property
allow.everyone.if.no.acl.foundtofalse. This is done via the Cluster Configuration. You can create the cluster with the default configuration and edit it later to add this setting.
For SASL/SCRAM authentication, you’ll set the user/password after the cluster is created. For encryption, you’ll want to use your own key created in AWS KMS.
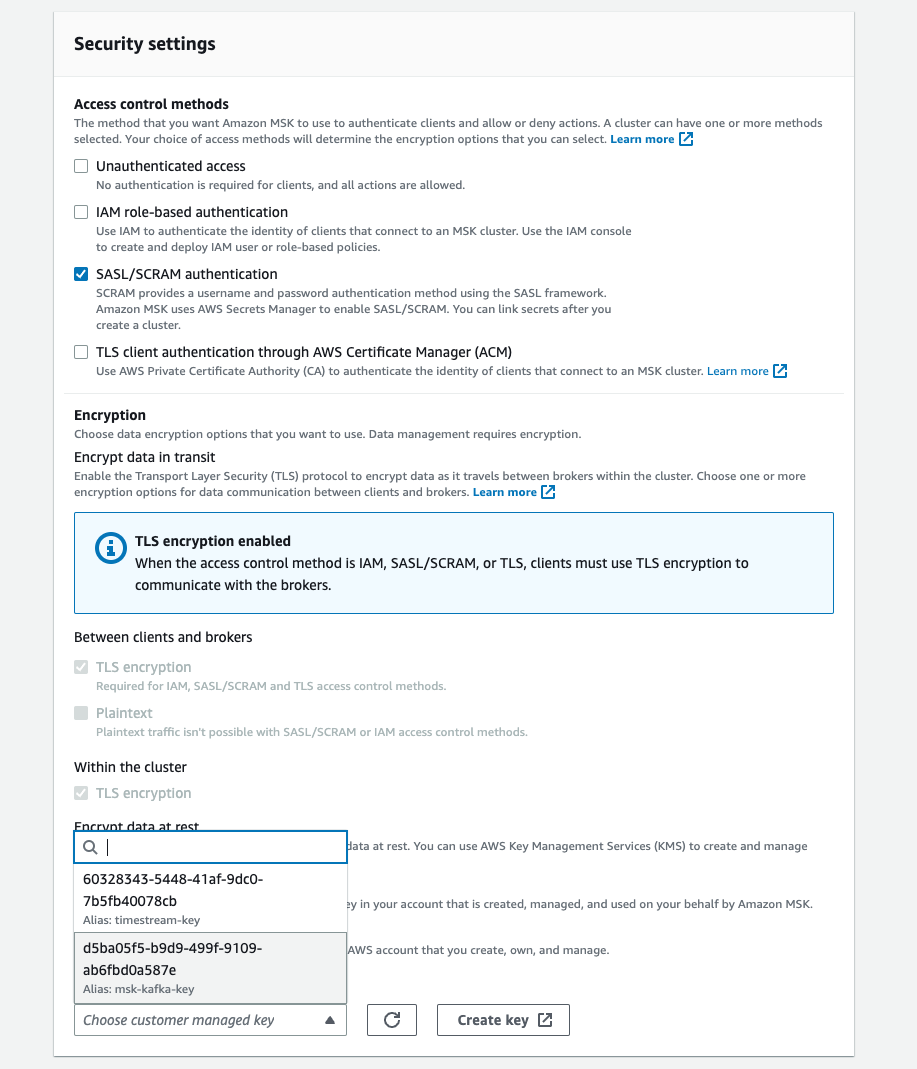
Once a cluster is created with these settings, you’ll find that the cluster properties allow you to Edit Public Access.

Setting up ACLs
Once you’ve set up public access, accessing the cluster remotely will give you a Not Authorized error to consumers and producers. You may see a message like Not Authorized to access group or Topic Authorization Failed. Even though you’ve enabled public access, setting up ACLs requires private access to the zookeeper nodes this one time to be able to perform this configuration. What you’ll need to do is set up an EC2 instance inside your MSK VPC but on a private subnet and then access the MSK cluster using the private zookeeper string.
Per the AWS docs:
- Create an EC2 instance using the Amazon Linux 2 AMI
- SSH as ec2-user
- Run the following, replacing $ZK_CONN with the Plaintext Apache ZooKeeper connection string from your AWS MSK
Client Informationbutton.

See the AWS docs for more details about the specific ACLs that you need to setup. We also often reference the Confluent Kafka ACL docs for knowing what the different permissions are.
Size your Cluster
Serverless vs. Provisioned Cluster Type
A serverless cluster automatically scales based on read/write throughput, while a provisioned cluster has a consistent number of brokers of a particular size. A serverless cluster makes sense for lower throughputs as there is a maximum of 200 MiB/second writes and 400 MiB/second reads, but the cluster will adjust to only charge for the throughput you use. You’ll pay per partition-hours as well, so a large number of partitions may be expensive.
A provisioned cluster will perform consistently depending on the instance type and number of brokers and would be recommended for larger production environments. For context, we currently send about 5k messages / second at a 1 MB average size at about 300 MB/second of throughput.
To find an optimal broker size, we reduced our instance types until our broker CPU usage was near 50% at the peak. We’ve found that an increase in partitions will linearly increase CPU usage and will substantially increase memory pressures on the cluster. For our workload at nearly 3000 partitions, a 3-broker cluster of kafka.m5.2xlarge nodes has worked reliably.
Creating a Topic
Using the configured instance, create a topic by using the kafka-topics.sh helper. Following the AWS MSK documentation, run the following commands:
Configure Monitoring Tools
For monitoring your cluster, we use the provectuslabs/kafka-ui docker image. If running a private kafka cluster, you’ll want it deployed in the same VPC as your cluster.
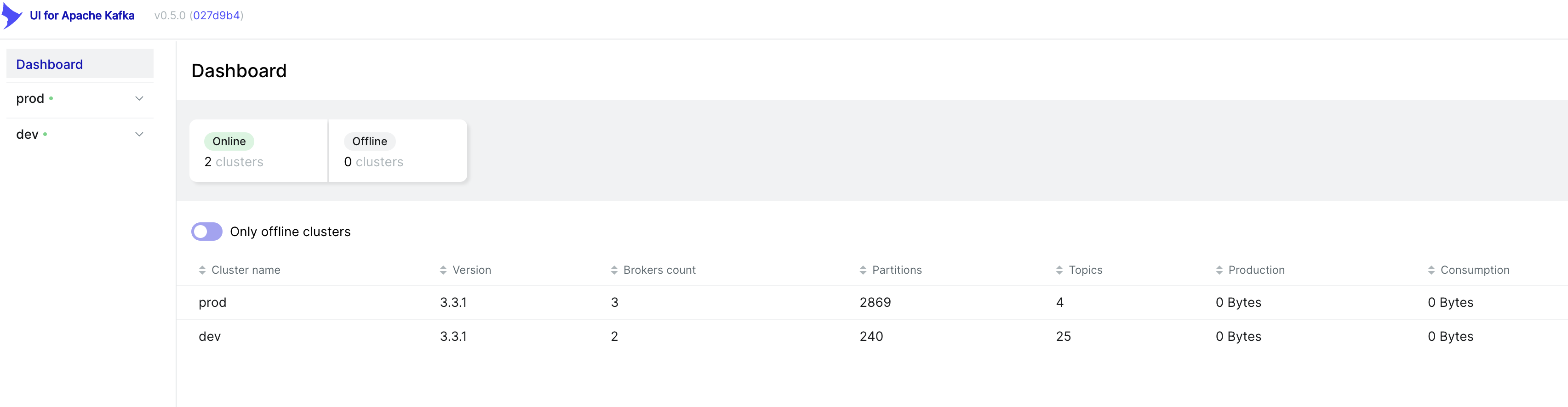
The tool gives you a few neat features:
- View the state of brokers in your cluster
- Monitor partitions in your topic, including their replication state.
- View messages in a particular topic, either live or scanning the newest ones in a partition.
- Monitor a consumer group to know how far behind it is, and how many members it has.
We’ve found it particularly useful for troubleshooting production issues with our clusters, such as identifying that a broker is down and causing write errors. In development, the tool was very useful to view the messages as raw strings, allowing troubleshooting other parts of our data processing pipeline.
Since we serialize our messages in kafka as JSON, they are easy to read and understand. Here’s an example of our message format, decompressed and formatted:
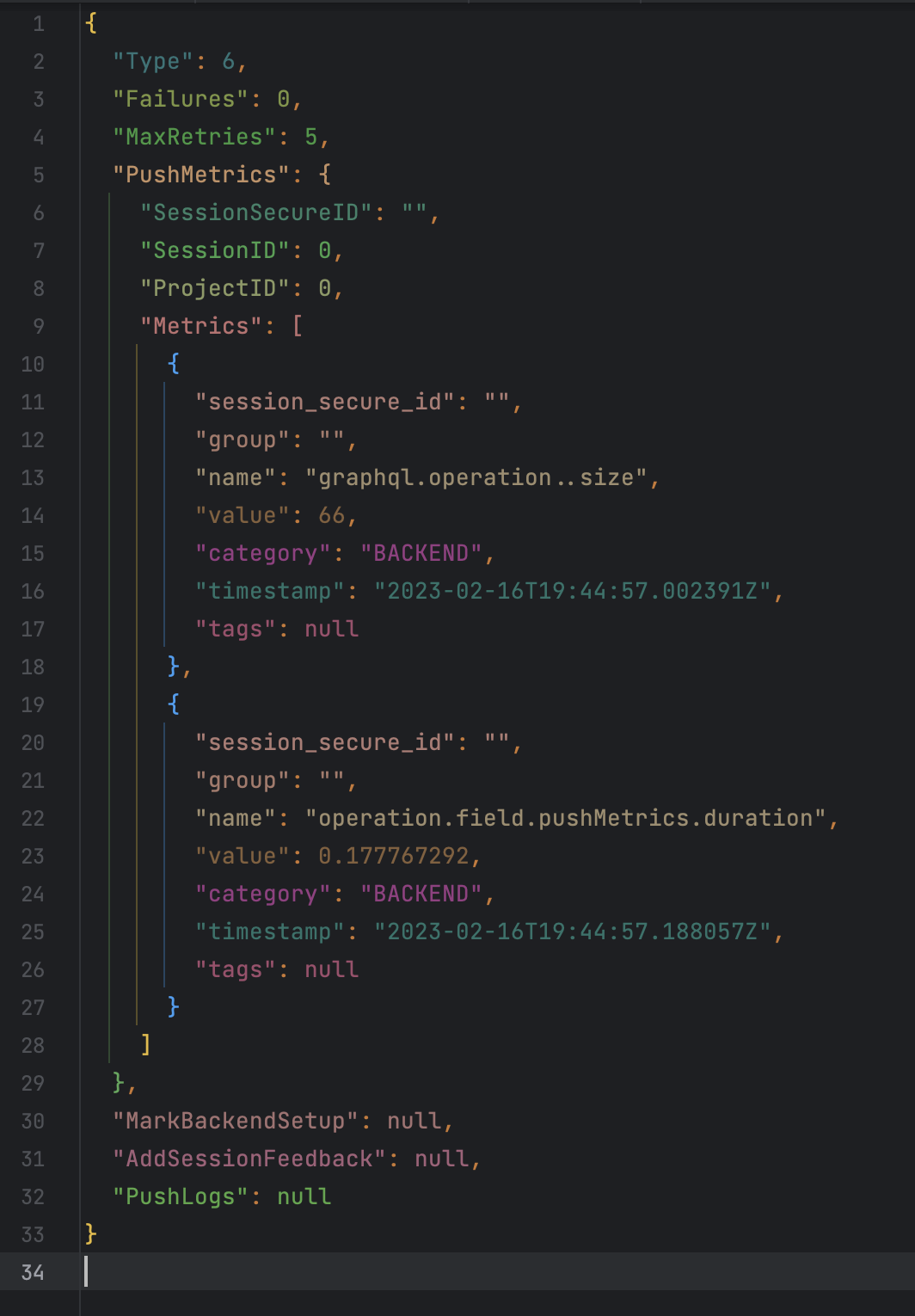
For more info about how we structure our data and configured our cluster, see our other blog. We have a lot of learnings there about how we defined our message model, configured log retention, and fixed a critical data loss issue caused by enabling log compaction.