Smart AI Agent Targeting with MCP Tools
Published September 22nd, 2025

Newer features are available with AgentControl
This tutorial was published in September 2025, before LaunchDarkly shipped several features that complement or supersede the targeting patterns shown below. The walkthrough still works, but for new builds you may want to use:
- Agent graphs: Externalize the multi-agent topology into a visual graph and combine it with the targeting rules in this tutorial
- Online evaluations and custom judges: Score live traffic per variation, including per-segment quality scores
- Prompt snippets: Reusable prompt fragments so you can compose region-specific or tier-specific instructions without duplicating
To learn more, read AgentControl.
Here’s what nobody tells you about multi-agentic systems: the hard part isn’t building them but making them profitable. One misconfigured model serving enterprise features to free users can burn $20K in a weekend. Meanwhile, you’re manually juggling dozens of requirements for different user tiers, regions, and privacy compliance and each one is a potential failure point.
Part 2 of 3 of the series: Chaos to Clarity: Defensible AI Systems That Deliver on Your Goals
The solution? LangGraph multi-agent workflows controlled by config targeting rules that intelligently route users: paid customers get premium tools and models, free users get cost-efficient alternatives, and EU users get Mistral for enhanced privacy. Use the LaunchDarkly REST API to set up a custom variant-targeting matrix in 2 minutes instead of spending hours setting it up manually.
What You’ll Build Today
In the next 18 minutes, you’ll transform your basic multi-agent system with:
- Business Tiers & MCP Integration: Free users get internal keyword search, Paid users get premium models with RAG, external research tools and expanded tool call limits, all controlled by AgentControl
- Geographic Targeting: EU users automatically get Mistral and Claude models (enhanced privacy), other users get cost-optimized alternatives
- Smart Configuration: Set up complex targeting matrices with LaunchDarkly segments and targeting rules
Prerequisites
✅ Part 1 completed with exact naming:
- Project:
multi-agent-chatbot - AgentControl:
supervisor-agent,security-agent,support-agent - Tools:
search_v2,reranking - Variations:
supervisor-basic,pii-detector,rag-search-enhanced
🔑 Add to your .env file:
Getting Your LaunchDarkly API Key
The automation scripts in this tutorial use the LaunchDarkly REST API to programmatically create configurations. Here’s how to get your API key:
To get your LaunchDarkly API key, start by navigating to Organization Settings by clicking the gear icon (⚙️) in the left sidebar of your LaunchDarkly dashboard. Once there, access Authorization Settings by clicking “Authorization” in the settings menu. Next, create a new access token by clicking “Create token” in the “Access tokens” section.
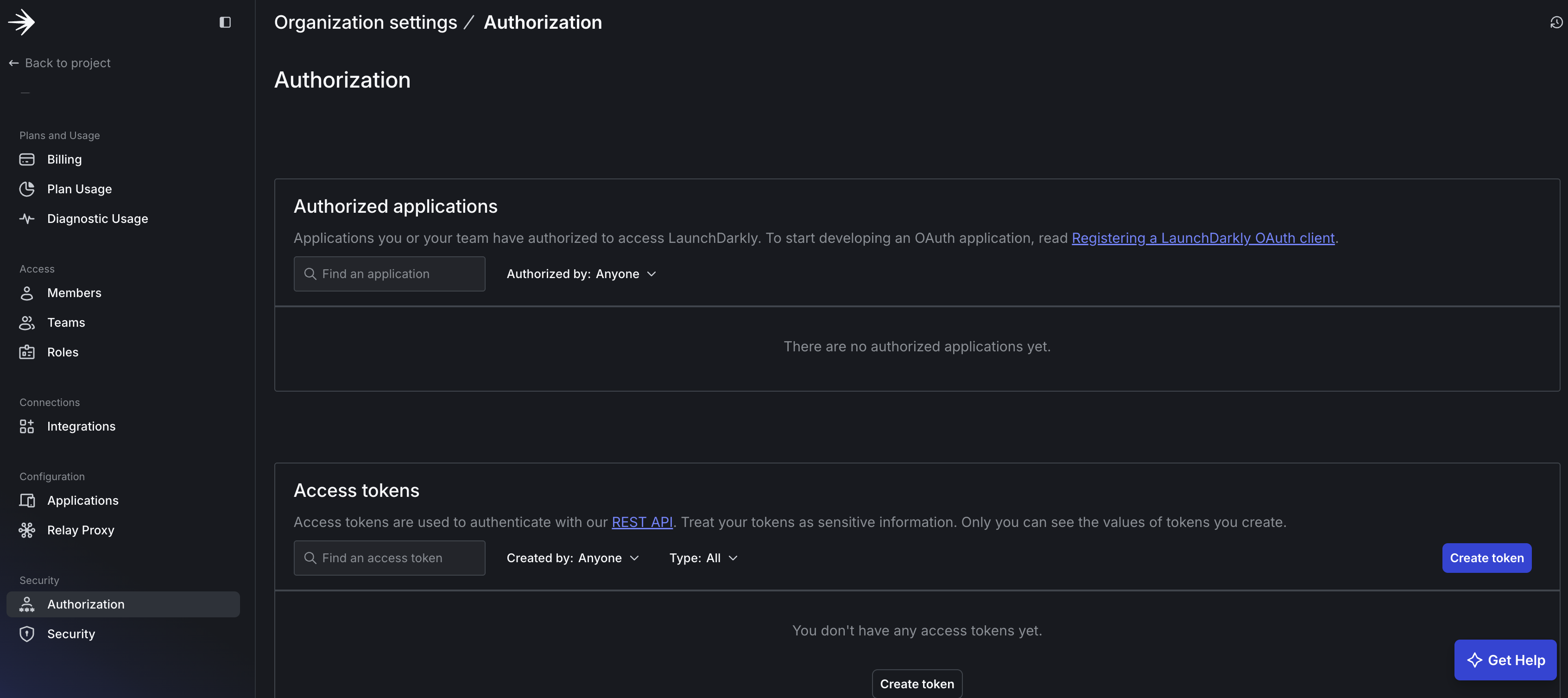
When configuring your token, give it a descriptive name like “multi-agent-chatbot”, select “Writer” as the role (required for creating configurations), use the default API version (latest), and leave “This is a service token” unchecked for now.
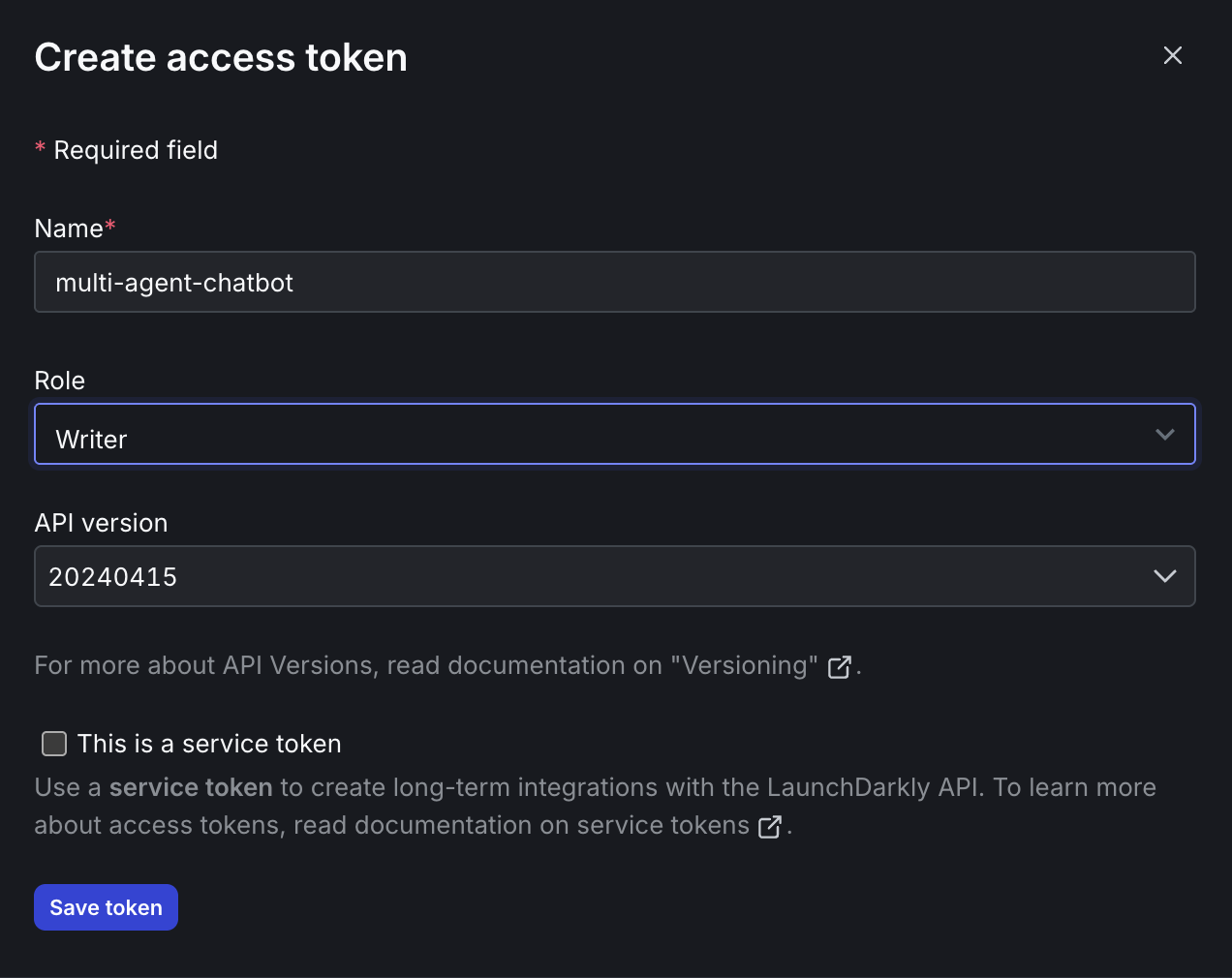
After configuring the settings, click “Save token” and immediately copy the token value. This is IMPORTANT because it’s only shown once!
Finally, add the token to your environment:
Security Note: Keep your API key private and never commit it to version control. The token allows full access to your LaunchDarkly account.
Step 1: Add External Research Tools (4 minutes)
Your agents need more than just your internal documents. Model Context Protocol (MCP) connects AI assistants to live external data and they agents become orchestrators of your digital infrastructure, tapping into databases, communication tools, development platforms, and any system that matters to your business. MCP tools run as separate servers that your agents call when needed.
The MCP Registry serves as a community-driven directory for discovering available MCP servers - like an app store for MCP tools. For this tutorial, we’ll use manual installation since our specific academic research servers (ArXiv and Semantic Scholar) aren’t yet available in the registry.
Install external research capabilities:
MCP Tools Added:
- arxiv_search: Live academic paper search (Paid users)
- semantic_scholar: Citation and research database (Paid users)
These tools integrate with your agents via LangGraph while LaunchDarkly controls which users get access to which tools.
Step 2: Configure with API Automation (2 minutes)
Now we’ll use programmatic API automation to configure the complete setup. The LaunchDarkly REST API lets you manage tools, segments, and AgentControl programmatically. Instead of manually creating dozens of variations in the UI, this configuration automation makes REST API calls to provision user segments, config variations, targeting rules, and tools. These are the same resources you could create manually through the LaunchDarkly dashboard. Your actual chat application continues running unchanged.
Configure your complete targeting matrix with one command:
What the script creates:
- 3 new tools:
search_v1(basic search),arxiv_searchandsemantic_scholar(MCP research tools) - 4 combined user segments with geographic and tier targeting rules
- Updated AgentControl:
security-agentwith 2 new geographic variations - Complete targeting rules that route users to appropriate variations
- Intelligently reuses existing resources:
supervisor-agent,search_v2, andrerankingtools from Part 1
Understanding the Bootstrap Script
The automation works by reading a YAML manifest and translating it into LaunchDarkly API calls. Here’s how the key parts work:
Segment Creation with Geographic Rules:
Model Configuration Mapping:
Customizing for Your Use Case:
To adapt this for your own multi-agent system:
-
Add your geographic regions in the YAML segments:
-
Define your business tiers:
-
Map your models in the script:
The script handles the complexity of LaunchDarkly’s API while letting you define your targeting logic in simple YAML.
Validating the Bootstrap Script
Expected terminal output:
In your LaunchDarkly dashboard, navigate to your multi-agent-chatbot project. You should see:
- AgentControl tab: Three configs (
supervisor-agent,security-agent,support-agent) with new variations - Segments tab: Four new segments (
eu-free,eu-paid,other-free,other-paid) - Tools tab: Five tools total (including
search_v1,arxiv_search,semantic_scholar)
Troubleshooting Common Issues:
❌ Error: “LD_API_KEY environment variable not set”
- Check your
.envfile contains:LD_API_KEY=your-api-key - Verify the API key has “Writer” permissions in LaunchDarkly settings
❌ Error: “config ‘security-agent’ not found”
- Ensure you completed Part 1 with exact naming requirements
- Verify your project is named
multi-agent-chatbot - Check that
supervisor-agent,security-agent, andsupport-agentexist in your LaunchDarkly project
❌ Error: “Failed to create segment”
- Your LaunchDarkly account needs segment creation permissions
- Try running the script again; it’s designed to handle partial failures
❌ Script runs but no changes appear
- Wait 30-60 seconds for LaunchDarkly UI to refresh
- Check you’re looking at the correct project and environment (Production)
- Verify your API key matches your LaunchDarkly organization
Step 3: See How Smart Segmentation Works (2 minutes)
Here’s how the smart segmentation works:
By Region:
- EU users: Mistral for security processing + Claude for support (privacy + compliance)
- Non-EU users: Claude for security + GPT for support (cost optimization)
- All users: Claude for supervision and workflow orchestration
By Business Tier:
- Free users: Basic search tools (
search_v1) - Paid users: Full research capabilities (
search_v1,search_v2,reranking,arxiv_search,semantic_scholar)
AWS Bedrock inference region
This geo-segmentation is fully correct for the non-Bedrock path (direct OpenAI / Anthropic / Mistral APIs) — EU vs non-EU routing of model, provider, and PII-redaction strictness works exactly as described. On the AWS Bedrock path it likewise segments the model and redaction correctly, but it cannot segment the AWS inference region: the region prefix is process-global (set once via BEDROCK_INFERENCE_REGION), so every Bedrock call in a deployment uses the same region regardless of the user’s EU/non-EU segment. Making the inference region a per-variation property is a planned LaunchDarkly enhancement; until then, run separate deployments per region if EU-region inference is a hard requirement.
Step 4: Test Segmentation with Script (2 minutes)
The included test script simulates real user scenarios across all segments, verifying that your targeting rules work correctly. It sends actual API requests to your system and confirms each user type gets the right model, tools, and behavior.
First, start your system:
Expected test output:
This confirms your targeting matrix is working correctly across all user segments!
Step 5: Experience Segmentation in the Chat UI (3 minutes)
Now let’s see your segmentation in action through the user interface. With your backend already running from Step 4, start the UI:
Open http://localhost:8501 and test different user types:
- User Dropdown: Find the user dropdown by using the >> icon to open the left sidebar menu.. Select different regions (eu, other) and plans (Free, Paid).
- Ask Questions: Try “Search for machine learning papers.”
- Watch Workflow: In the server logs, watch which model and tools get used for each user type.
- Verify Routing: EU users get Mistral for security. Other users get GPT. Paid users get MCP tools.
What’s Next: Part 3 Preview
In Part 3, we’ll prove what actually works using controlled A/B experiments:
Set up Easy Experiments
- Tool Implementation Test: Compare search_v1 vs search_v2 on identical models to measure search quality impact
- Model Efficiency Analysis: Test models with the same full tool stack to measure tool-calling precision and cost
Real Metrics You’ll Track
- User satisfaction: thumbs up/down feedback
- Tool call efficiency: average number of tools used per successful query
- Token cost analysis: cost per query across different model configurations
- Response latency: performance impact of security and tool variations
Instead of guessing which configurations work better, you’ll have data proving which tool implementations provide value, which models use tools more efficiently, and what security enhancements actually costs in performance.
The Path Forward
You’ve built something powerful: a multi-agent system that adapts to users by design. More importantly, you’ve proven that sophisticated AI applications don’t require repeated deployments; they require smart configuration.
This approach scales beyond tutorials. Whether you’re serving 100 users or 100,000, the same targeting principles apply: segment intelligently, configure dynamically, and let data guide decisions instead of assumptions.
Related tutorials
- Build a LangGraph Multi-Agent system in 20 Minutes - Part 1: the multi-agent system this tutorial layers targeting on top of
- Proving ROI with data-driven AI agent experiments - Part 3: A/B test the targeted variations you just built
- Beyond n8n for Workflow Automation: Agent Graphs - Combine targeting with visual graph topology and per-node monitoring
- Build AgentControl configs with Agent Skills - Generate the agent and targeting configurations from natural-language prompts
- Offline Evaluation of RAG-Grounded Answers - Validate each targeted variation against a reference dataset before rollout
Questions? Issues? Reach out at aiproduct@launchdarkly.com or open an issue in the GitHub repo.