A Deeper Look at LaunchDarkly Architecture: More than Feature Flags
A Deeper Look at LaunchDarkly Architecture: More than Feature Flags
Published October 08, 2025

When developers first encounter LaunchDarkly, they often see it as a feature flag management tool. Turns out calling LaunchDarkly a feature flag tool is like calling a Swiss Army knife “a device for opening wine bottles.” Even though that would still be useful. Although technically true, you’re missing about 90% of the picture.
LaunchDarkly has quietly evolved into a full feature delivery platform that happens to use flags as the foundation for four interconnected pillars: Release Management, Observability & Monitoring, and Analytics & Experimentation, and AgentControl. Understanding how these pillars work together, including the backend infrastructure reveals why LaunchDarkly has become mission-critical for modern software delivery.
The Foundation: Feature Flag Management
At the heart of LaunchDarkly lies its feature flag management system. Think of feature flags as the control switches for your application’s behavior. But unlike traditional configuration management, LaunchDarkly’s flags are dynamic, real-time, and incredibly sophisticated.
Feature flag management serves as the foundation layer because it enables everything else. Without the ability to control feature visibility and behavior at runtime, none of the other pillars could function. This foundation includes:
- Feature flags: Binary or multi-variant toggles that control feature availability.
- AgentControl: Dynamic configuration for AI model parameters and behaviors.
- Targeting rules: Sophisticated logic for determining who sees what features.
- Contexts: User, device, and organizational information for personalized experiences.
I spent an embarrassing amount of time in my hammock thinking about why this is the foundation layer. The answer is simple: without runtime control over features, you’re back to deploying code every time you want to change something. And if you’ve ever been on-call during a Friday deployment that went sideways, you know that’s its own level of trauma.
The Four Pillars (Or how to sleep through deployments)
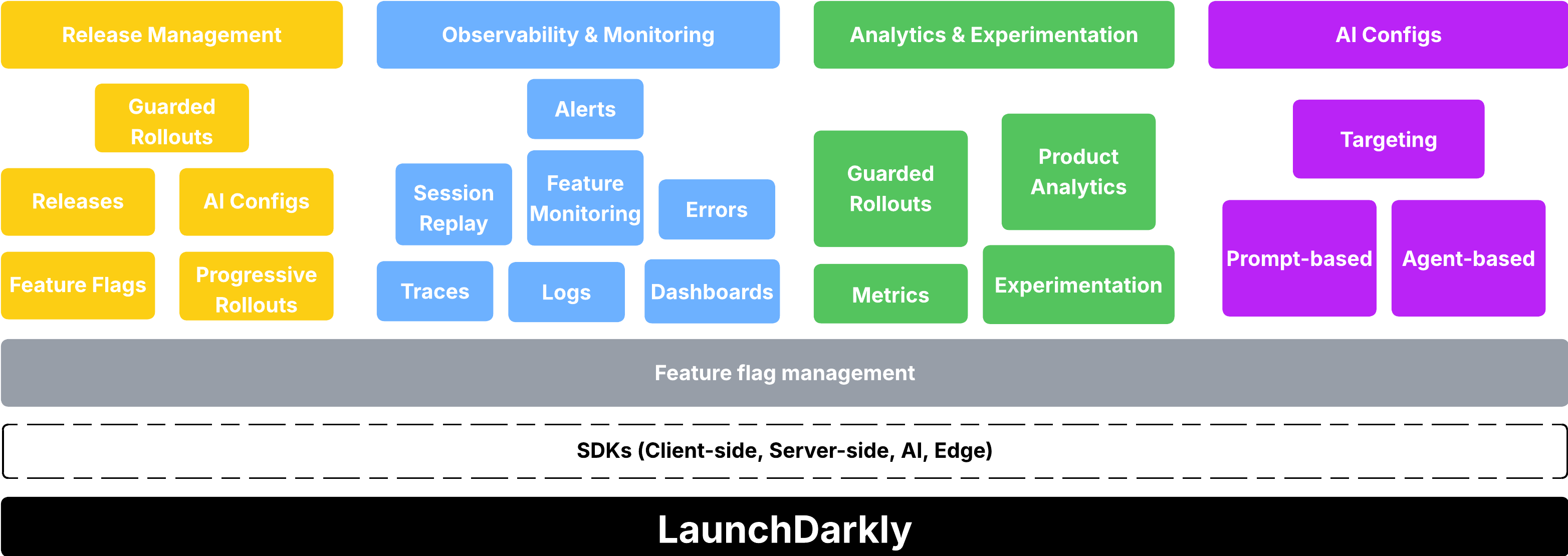
1. Release Management (Yellow)
The Release Management pillar focuses on safely delivering features to production. This includes:
Releases: Traditional feature rollouts with full control over timing and audience.
Guarded Rollouts: Progressive rollouts combined with real-time monitoring and automatic rollback capabilities. This is the feature that will single-handedly help you get more sleep. When you enable a guarded rollout, LaunchDarkly monitors metrics like error rates, latency, and custom business metrics. If it detects a regression, it can automatically roll back the change before users are impacted.
Progressive Rollouts: Automated gradual rollouts that increase traffic to a new feature over time (e.g., 10% -> 25% -> 50% -> 100%)
The key insight here is Release Management isn’t about deploying code anymore. It’s about deploying business value while your code sits safely in production, waiting for permission to run.
2. Observability & Monitoring (Blue)
This pillar answers life’s most important production question: “Wait, what’s happening right now?” This includes:
Session Replay: Record and replay user sessions to understand exactly what users experienced. For instance, if the user says a button didn’t work, then you can literally watch what they did.
Feature Monitoring: Track feature health, performance, and adoption in real-time.
Alerts: Proactive notifications when metrics breach thresholds.
Errors, Logs, Traces: The ultimate trio of debugging, all in one place, all correlated with which flags were active when things went sideways.
Dashboards: Customizable visualizations of all observability data.
What makes LaunchDarkly’s observability unique is the feature-level granularity. Traditional monitoring says “error rate increased at 2:47pm.” LaunchDarkly says “error rate increased at 2:47pm when you toggled the new-payment-processor flag to 30% rollout.” One of these lets you fix the problem from your hammock. The other leads you down a git rabbit hole.
3. Analytics & Experimentation (Green)
The Analytics & Experimentation pillar helps teams make data-driven decisions:
Experimentation: Full-featured A/B testing and multivariate experiments. Run controlled experiments to measure the impact of features on business metrics.
Metrics: Track both engineering metrics (error rates, latency) and business metrics (conversion, revenue, engagement).
Guarded Rollouts (also appears here): While primarily a release mechanism, Guarded Rollouts use Experimentation methodology to automatically detect regressions during rollouts.
The Experimentation pillar transforms feature flags from simple on/off switches into scientific instruments for measuring impact.
4. AgentControl (Purple)
The unveiling of AgentControl marks a shift in LaunchDarkly’s shift from simply creating and storing feature flag values to storing values related to Large Language Models (LLMs). This gives way to pretty neat opportunities like customizing, testing, and rolling out new LLMs.
How the Pillars are Interconnected
The four pillars aren’t just sitting next to each other making awkward small talk. They’re in a deeply committed relationship with constant communication. Here’s how:
- Release Management -> Observability: When you toggle a flag or start a rollout, observability tools immediately begin tracking the impact. Error rates, traces, and logs are automatically correlated with the flag change.
- Observability -> Analytics: The data collected through monitoring feeds directly into Experimentation and analytics. You’re not just watching for errors; you’re measuring business impact.
- Analytics -> Release Management: Experiment results inform which variations to roll out. Metrics from guarded rollouts trigger automatic decisions (rollback or continue).
- AgentControl -> All Pillars: AgentControl configs add a dynamic layer across the ecosystem:
- To Release Management: Model versions, prompts, and parameters can be toggled like features, enabling safe AI deployments.
- To Observability: Track model performance, latency, token usage, and output quality in real-time.
- To Analytics: A/B test different prompts, models, or parameters to optimize AI outcomes and measure business impact.
- Feature Flags Enable Everything: Without the foundational flag management system, none of these capabilities would work. Flags are the control point that makes progressive delivery, real-time monitoring, and controlled Experimentation possible.
The Infrastructure: Flag Delivery Network (FDN)
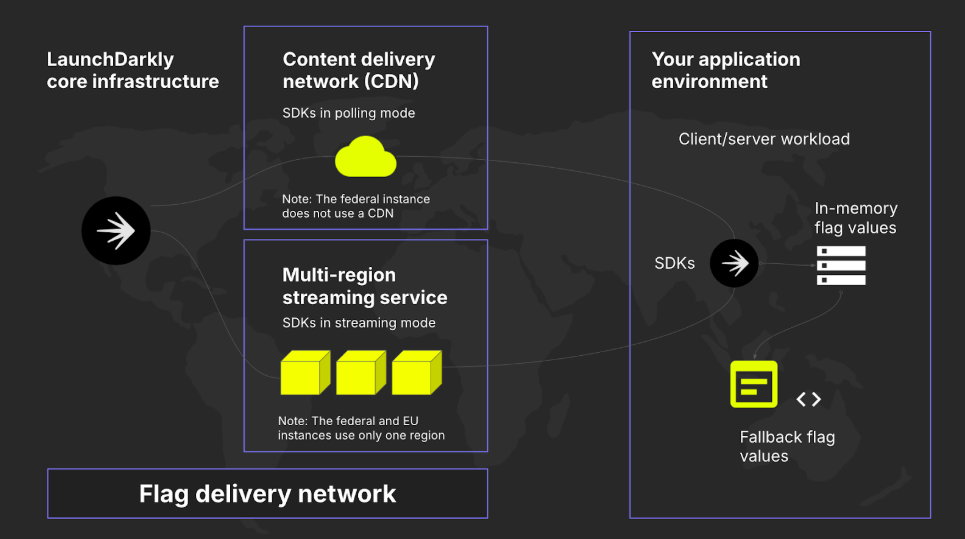
Understanding the pillars is only half the story. The infrastructure that delivers flags to your applications is equally crucial. LaunchDarkly’s Flag Delivery Network is what makes real-time feature control possible at massive scale.
What is the FDN?
The Flag Delivery Network is LaunchDarkly’s proprietary infrastructure combining:
- LaunchDarkly’s core infrastructure: Central flag management and rule evaluation engine.
- Content Delivery Network (CDN): Over 100 points of presence globally.
- Multi-region streaming service: Real-time flag updates via persistent connections.
Think of it as a specialized CDN, but instead of delivering static assets, it delivers feature flag configurations and streams real-time updates.
How the FDN Works
- Flag Creation: A developer, PM, or operator creates or modifies a flag in the LaunchDarkly dashboard.
- Global Distribution: The flag configuration is immediately pushed to all CDN edge locations worldwide.
- SDK Connection: Your application’s LaunchDarkly SDK connects to the nearest CDN point of presence.
- Initial Load: The SDK retrieves all flag configurations and stores them in memory.
- Real-time Updates: The SDK maintains a streaming connection; when flags change, updates arrive in milliseconds.
- Local Evaluation: Flag rules are evaluated locally in your application, which means no round-trip to LaunchDarkly required for each flag check.
SDK Modes: Polling vs. Streaming
LaunchDarkly SDKs can operate in two modes: streaming mode or polling mode.
Streaming Mode (recommended for server-side SDKs):
- Maintains a persistent connection to the FDN.
- Receives flag updates in real-time.
- Ideal for long-running applications like backend services.
Polling Mode (common for mobile/client-side SDKs):
- Periodically checks for flag updates.
- Lower resource usage on mobile devices.
- Configurable polling interval.
The Six Layers of Resilience
LaunchDarkly’s architecture includes multiple layers of failover to ensure flags are always available:
- In-memory cache: SDKs store flags locally; if the network fails, your app continues working.
- Fallback values: Every flag evaluation includes a default fallback value.
- CDN redundancy: 100+ global Points of Presence (POPs) ensure low latency and high availability.
- Multi-region infrastructure: LaunchDarkly’s core systems span multiple cloud regions.
- SDK resilience: Automatic retry logic and circuit breakers.
- Relay Proxy option: Deploy your own local flag cache for maximum control.
What this means in practice: your app never depends on LaunchDarkly being reachable. Flags work even during a complete LaunchDarkly outage.
Putting It All Together: A Real-World Scenario
Let me walk you through how this actually works in practice. Picture this: your team wants to launch a new checkout flow. In the old days (2023), this would involve:
- Extensive staging testing.
- A carefully planned deployment window.
- Someone’s weekend.
- Hoping for the best.
Now, it looks more like:
Step 1: Release
- Create feature flag new-checkout-flow.
- Configure configs for the personalized product recommendation model (prompt version, temperature, model selection).
- Configure targeting rules (start with your internal test accounts, because you’re not a monster).
- Start a guarded rollout to 10% of production traffic.
Step 2: Flag Delivery
- Flag configuration and config hit the FDN globally (this happens in milliseconds, which is faster than you can say “Jenkins pipeline”).
- Your mobile and web SDKs receive the update via their streaming connections.
- Flags are evaluated locally in-memory, adding exactly zero latency to your checkout flow.
Step 3: Observability Does Its Thing
- Session replay starts capturing user interactions with the new flow.
- Traces show checkout API performance in real-time.
- Error monitoring tracks any exceptions (there will be exceptions, there are always exceptions).
- Dashboards update with adoption metrics and AI performance indicators.
- Everything comes back as green.
Step 4: Analytics & Decision Making
- Metrics automatically track conversion rate, cart abandonment, purchase value.
- AI-specific metrics measure recommendation click-through rates and relevance scores.
- Guarded rollout monitors for regressions (error rate, latency, AI hallucinations, angry user emails).
- A/B test different prompt variations or model parameters to optimize recommendations.
- If metrics look good: automatic progression to 25% -> 50% -> 100%.
- If metrics look bad: automatic rollback before your on-call engineer finishes their coffee.
- You receive a Slack notification.
Step 5: The Result
- Feature safely released with automated safeguards.
- AI models deployed and optimized without risking production.
- Full visibility into user experience and system health.
- Data-driven decision on whether to keep the feature and which config performs best.
- Zero code deploys after the initial setup.
- You solved this entire problem without leaving your hammock.
Why This Architecture Matters
LaunchDarkly’s architecture represents a fundamental shift in how we think about software delivery:
Traditional Approach: Deploy -> Hope -> React to incidents -> Debug -> Fix -> Deploy again.
LaunchDarkly Approach: Deploy once -> Control via flags -> Monitor continuously -> Experiment safely -> Optimize based on data.
The key innovation is making the feature flag the control point for delivery, observability, Experimentation and AgentControl. This creates a closed feedback loop:
- Release Management provides the controls (the steering wheel).
- Observability provides the visibility (the headlights and dashboard).
- Analytics provides the insights (the GPS telling you which route is actually faster).
- AgentControl provide the intelligence (the adaptive cruise control that adjusts based on conditions).
- Feature flags tie it all together (they’re the guardrails, ensuring the car stays on the road).
Conclusion
LaunchDarkly isn’t just a feature flag tool, but it’s a complete feature delivery platform built on four interconnected pillars. The Flag Delivery Network ensures that control decisions made in the dashboard reach your applications globally in milliseconds, while multiple layers of resilience guarantee availability even during outages. Understanding this architecture helps explain why LaunchDarkly has become essential infrastructure for companies that need to ship software quickly without breaking things.
The combination of real-time control, comprehensive observability, data-driven experimentation, and intelligent AI management, built on a foundation of reliable, fast feature flag evaluation, enables true continuous delivery.
Whether you’re managing a handful of flags, orchestrating complex progressive rollouts across a global user base, or safely deploying and iterating on AI models with the same rigor as your traditional features, LaunchDarkly’s architecture scales to meet your needs while keeping the developer experience simple and the operational risk low.