The AI Iteration Loop for Deploying Reliable Agents with LangGraph
Published May 21, 2026

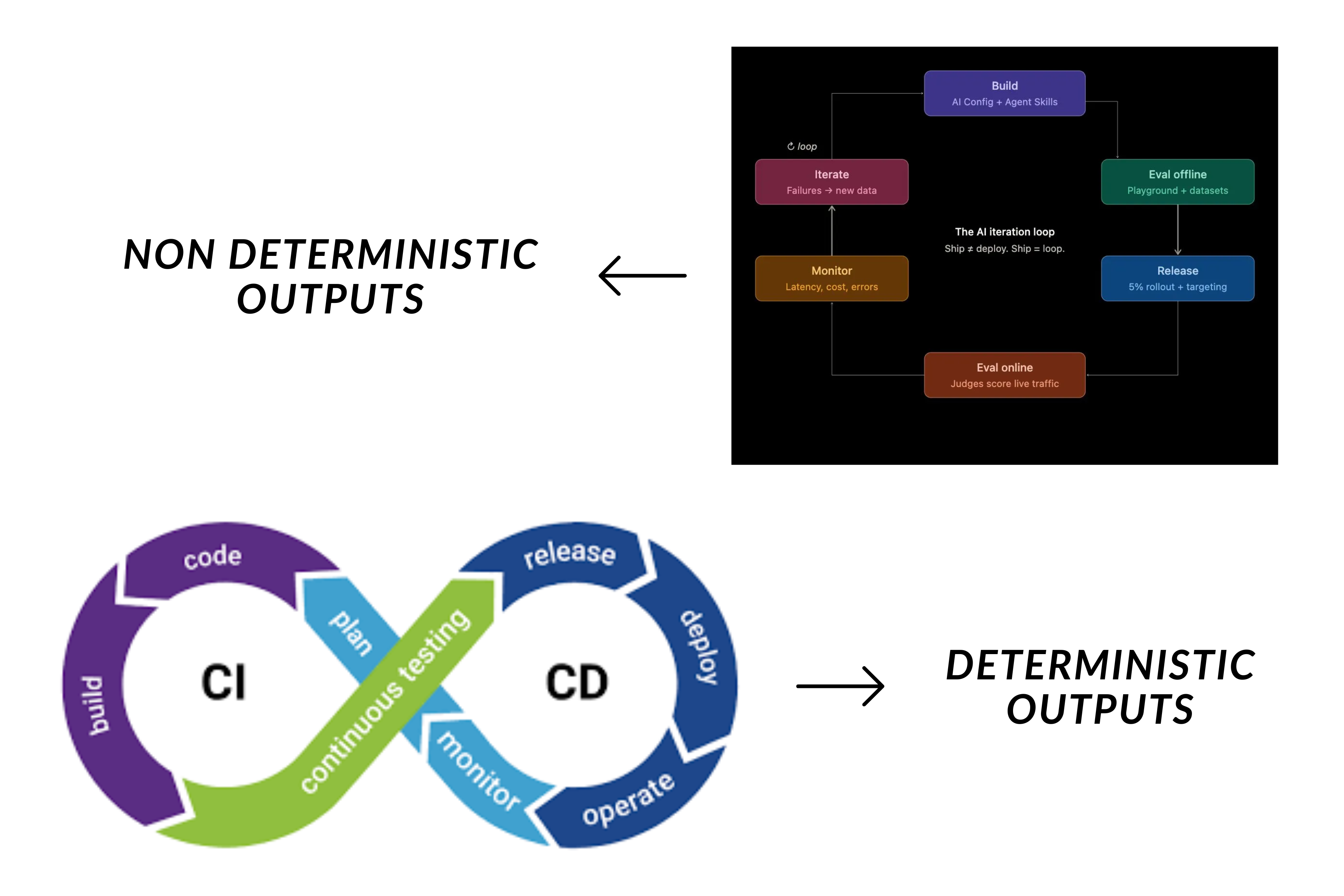
Engineers know the rhythm of continuous integration and continuous deployment (CI/CD): write the code, run tests, deploy, monitor.
The AI iteration loop follows the same structure, but adapts to systems like LLMs where nondeterministic outputs are the predicted norm. In these situations, instead of asserting exact outputs for LLM responses, you evaluate the quality of the response on a spectrum.
A decline in code quality can be tracked back to the latest git commit. With LLMs there are multiple points of drift including changes to model provider, weight updates, user behavior shifts.
This means we need a continuous loop that builds, evaluates on test data, releases, evaluates again on live data, monitor. And each pass through the loop feeds the next, which leads to the iteration.
A good way to set up a complete loop is by using feature flags as the kill/switch mechanism, AgentControl for managing model changes, variations/targeting for selecting which users experience a specific variation, offline/online evaluations for comparing variation impact, guarded rollouts, and observability.
In this tutorial, we’ll explore the first steps in the AI iteration loop starting with feature flags, AgentControl, and variations/targeting for a interior design agent.
AI Configs are called AgentControl configs
LaunchDarkly’s AI configs product was renamed to AgentControl. The MCP server endpoints, slash commands, and some skill names still use the aiconfigs slug, and the resource itself is still commonly called a “config.” This tutorial uses the current product name and keeps the legacy slugs in code and commands where they still apply.
The Decor Agent
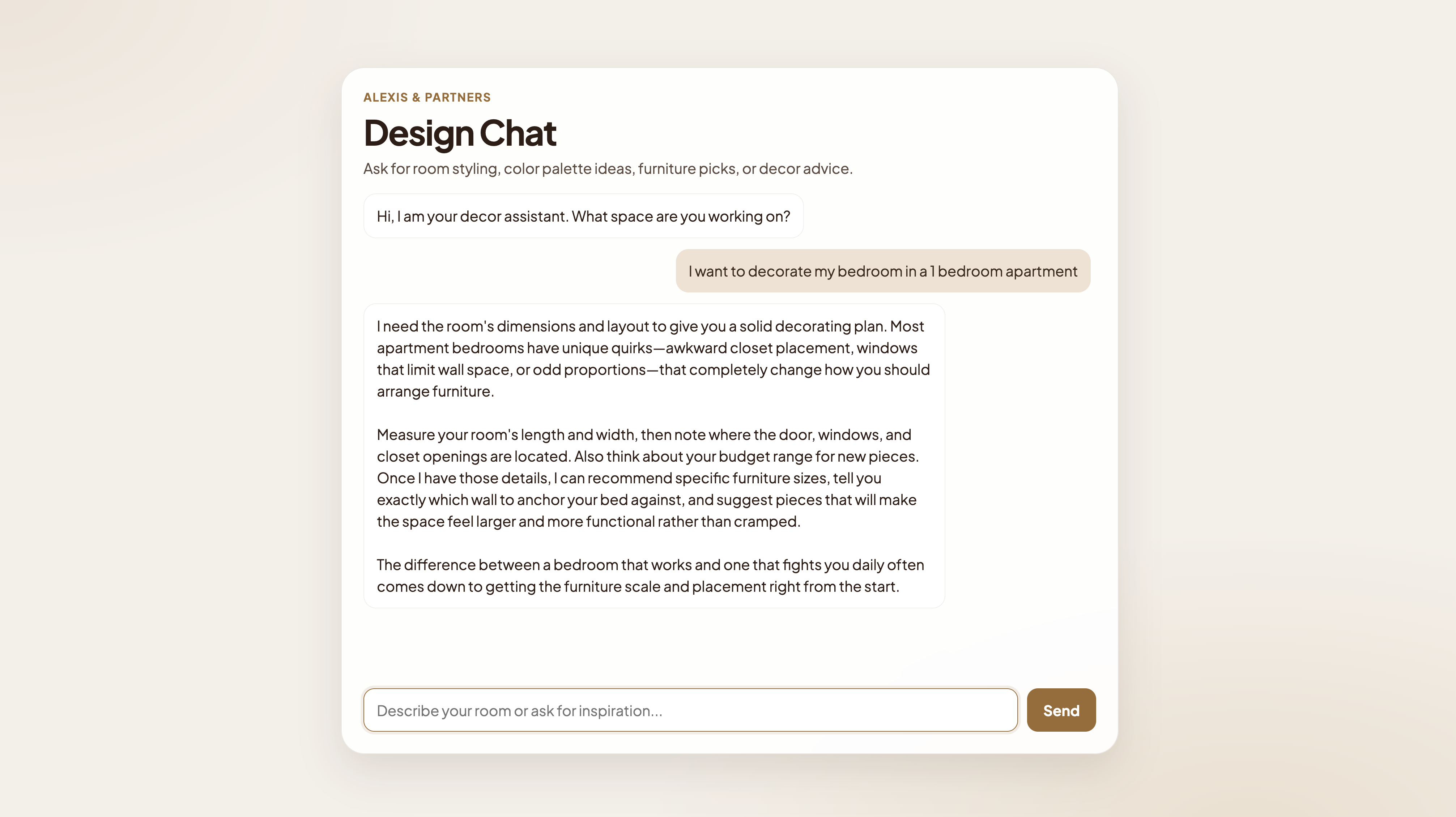
The Decor Agent is a LangGraph agent that gives confident, specific interior design advice. Users ask Decora, a senior interior design advisor, about colors, layouts, and trends. The assistant routes each question to one of three specialist tools, synthesizes a short opinionated response, and returns it.
The main agent uses three skills:
- the style advisor to help identify decor themes,
- the room planner for understanding the right decor based on room dimensions, and
- the trendspotter, which discovers emerging design trends outside traditional styles, such as whimsical or dopamine decor.
Prerequisites
To complete this tutorial, you must have the following prerequisites:
- A LaunchDarkly account with an AI project and access to your LaunchDarkly SDK key
- A hosted MCP server configured to use feature management, AgentControl configs, and observability. To learn how to install a hosted MCP server, read LaunchDarkly hosted MCP server.
- An Anthropic API key for Claude Sonnet
- Claude Code (or another Claude Agent SDK client) with the LaunchDarkly agent skills installed and the LaunchDarkly MCP server configured.
This setup assumes you’ll be working in Claude Code Desktop, but feel free to use other coding assistants.
All code for this tutorial can be found in this GitHub repository.
Before getting started, use the docs to setup LaunchDarkly’s hosted MCP Servers for feature management, AgentControl configs, and observability.
Now, you can add the SDKs and dependencies you’ll need to run through the demo.
Install LaunchDarkly’s Python SDKs
Then update the requirements.txt file with these packages:
Optionally, you can test the app yourself by starting the server. Here’s how:
Demo walkthrough
For the demo, we’ll create a LaunchDarkly project and run the following prompts in Claude Code to create the decor-agent feature flag, the AgentControl configs, and variations and targeting to control which users can access features on the “free” and “premium” plans.
1. Create the LaunchDarkly Project
Navigate to the LaunchDarkly UI and create the project with a project key.
Grab the project’s SDK key and LaunchDarkly project key and place them in your .env file before we continue prompting in the Claude Code chat.
2. Feature flags as agent gates
Feature flags have long been a staple of traditional software, used to control rollouts and ship with confidence.
In agentic systems, they take on a new role as an access gate for the agent itself. Wrapping an agent or skill in a flag gives you a runtime switch that decides whether that capability is reachable at all.
When it’s off, the call short-circuits before it hits the model, and the user sees a graceful fallback. The flag becomes a kill switch you can flip without redeploying.
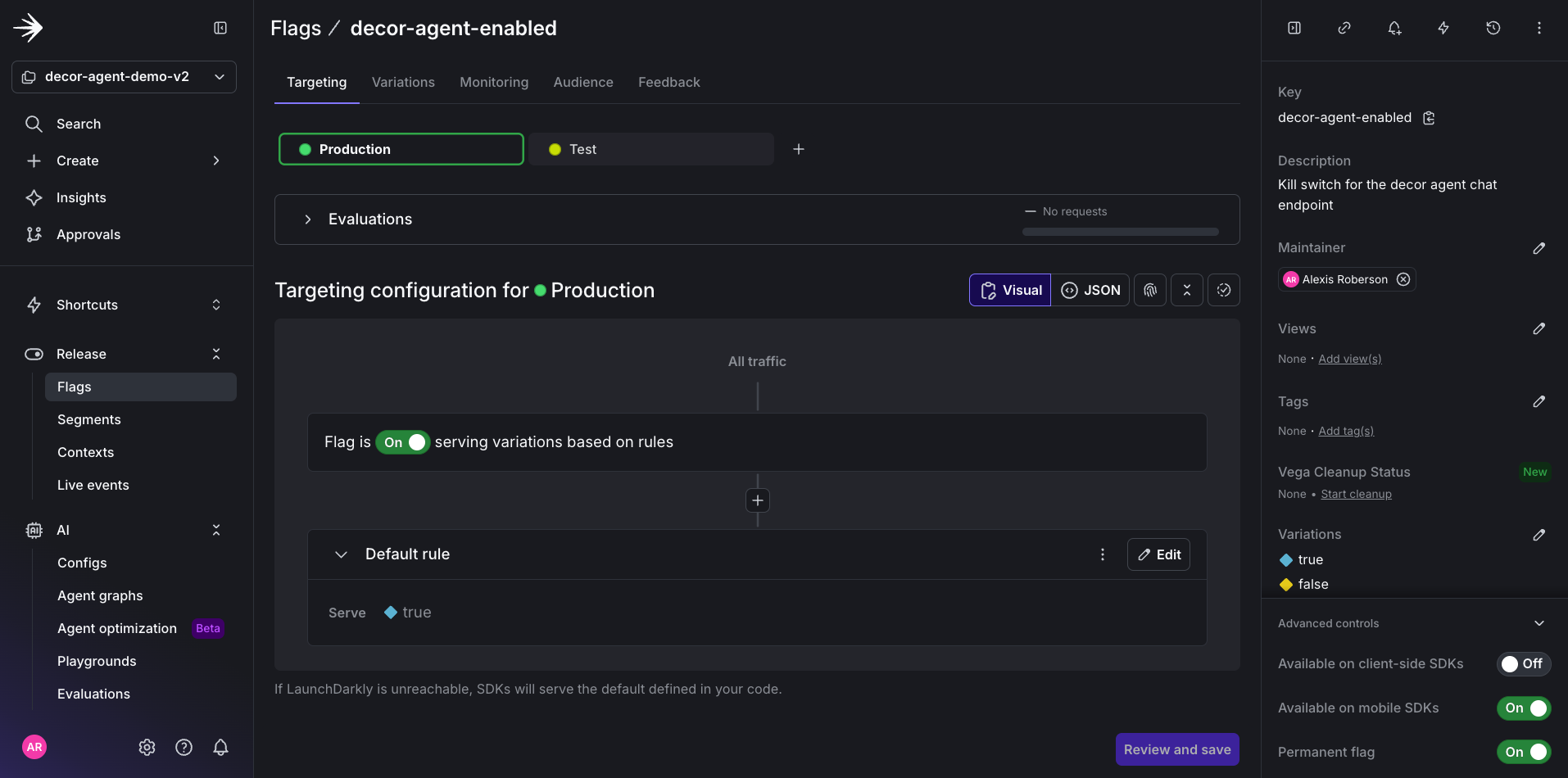
Let’s execute this prompt in the chat to create the feature flag:
Output:
Verify the flag has been created and is toggled on in the LaunchDarkly UI.
You can test this gate by toggling the feature flag off. You should see a maintenance message showing access to the chat assistant has been removed for now.
This is a basic representation of the power of gating your agents.
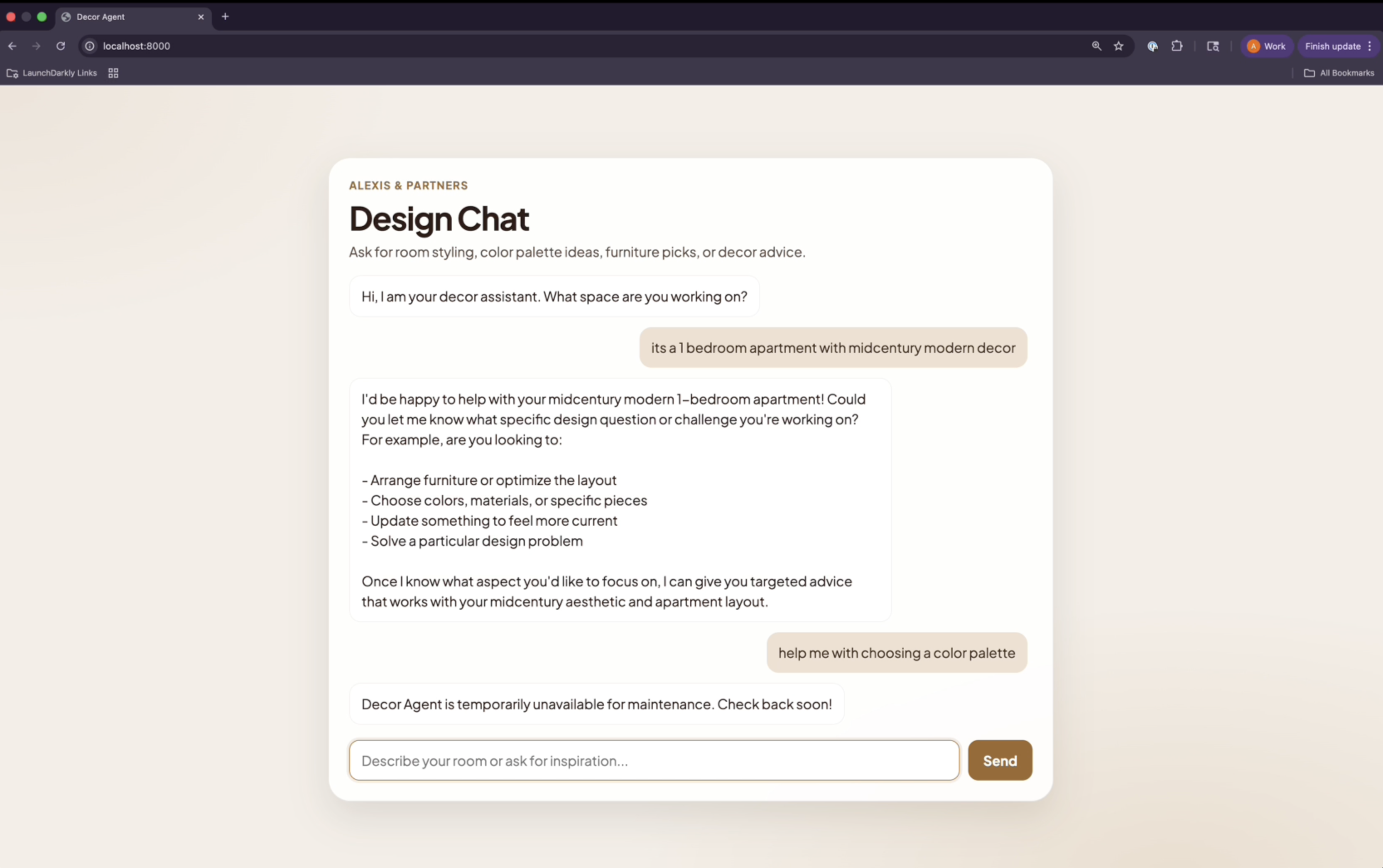
Click to enable the flag again and continue the demo.
3. Setting up AgentControl configs
Now, create four AgentControl configs to represent the overall agent and the three agent skills: style-advisor, room-planner, and trend-spotter.
Use AgentControl configs in completion mode
This demo uses completion mode to keep the focus on the iteration loop foundation: flags, variations, and targeting.
For multi-agent systems used in production, we recommend using agent mode, which manages tool definitions, instructions, and per-agent metadata in LaunchDarkly, rather than in your application code, and allows per-agent monitoring out of the box.
The targeting, variation, and evaluation patterns in this tutorial apply to both modes.
In the decor-agent code directory, there is a file calleddecor-agent/app/prompts.py which contains all of the system prompts for each AI component. These will be the prompts transferred to LaunchDarkly to establish the behavior of the overall agent and the three agent skills.
Now, let’s create each AgentControl config by running the following prompt:
Output:
The four configs are fully set up in decor-agent-demo-v2:
And you can always verify the prompts worked in the UI.
For example, if you view the decor-agent-main AI Config, you should be able to see the transferred prompt from prompts.py.
Click to expand the decor-agent-main system prompt
4. Variations and targeting
Because AI agents are nondeterministic, the most effective way to test output quality is by testing multiple variations of the same AI Config.
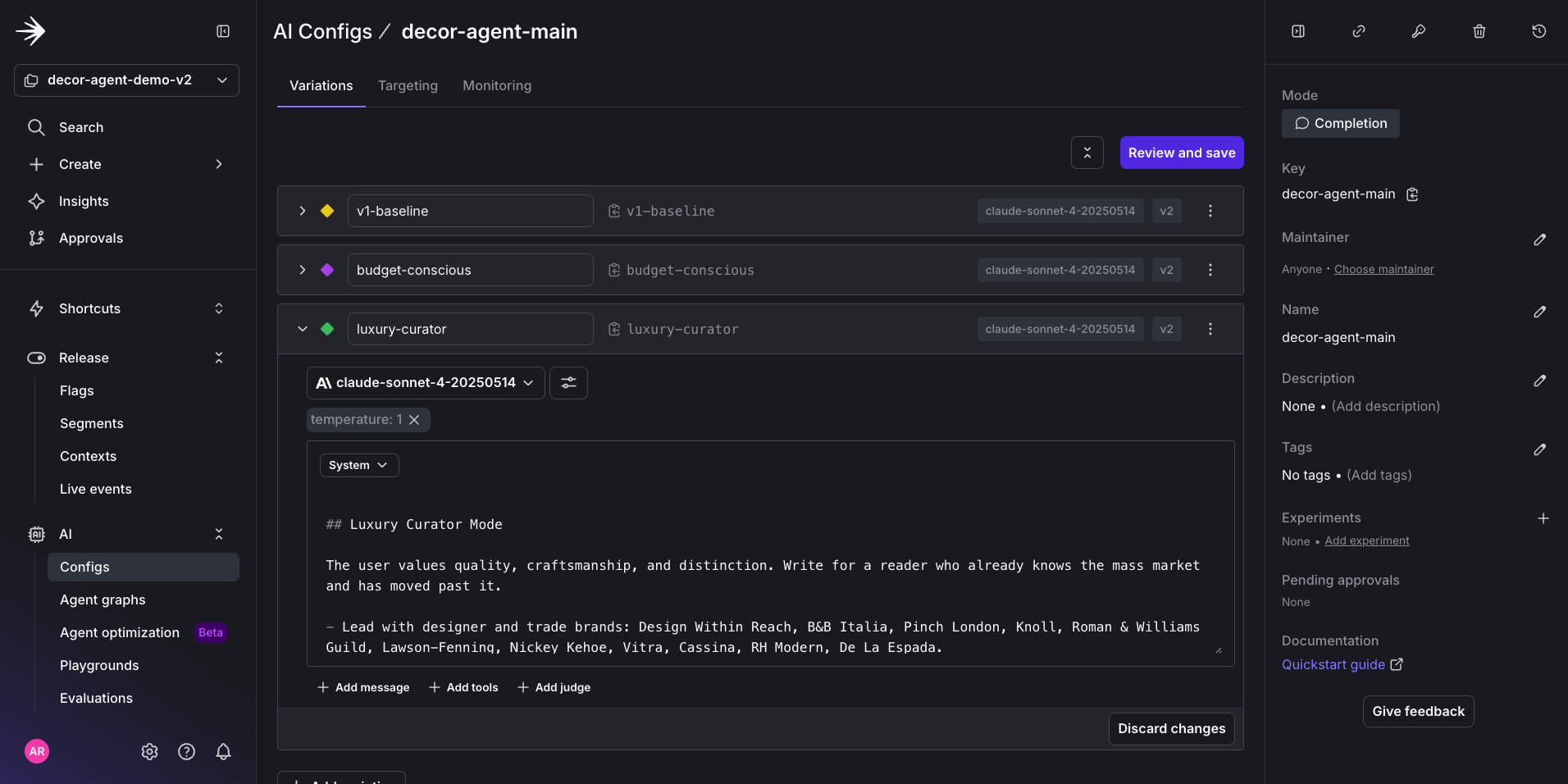
And in this case, we will create two new variations for the decor-agent-main AI Config:
Variations aren’t limited to prompt changes. Each variation can override the model, temperature, and max_tokens independently. Here, the budget-conscious variation runs on a cheaper, faster Haiku model to keep free-tier costs down, while the luxury-curator variation stays on Sonnet for richer, more nuanced recommendations.
The prompt for these variations will be almost identical to the decor-agent-main, except each variation contains more granular constraints to ensure they’re called for the right scenario.
Here’s a prompt to create the variations:
Click to expand the variation create prompt
Output:
We should also be able to see the newly created AI Config variations in the LaunchDarkly UI under the decor-agent-main config.
To determine which user is exposed to a certain variation, we can set up targeting that determines access.
5. Targeting for variation
For this tutorial, we can create two tiers called “free” and “premium.” All users will have access to the budget-conscious variation, but only premium users get access to the luxury-curator variation.
To configure this in the LaunchDarkly UI, use this prompt in Claude:
Output:
Here is how the successful outcome of this prompt appears in the LaunchDarkly UI:
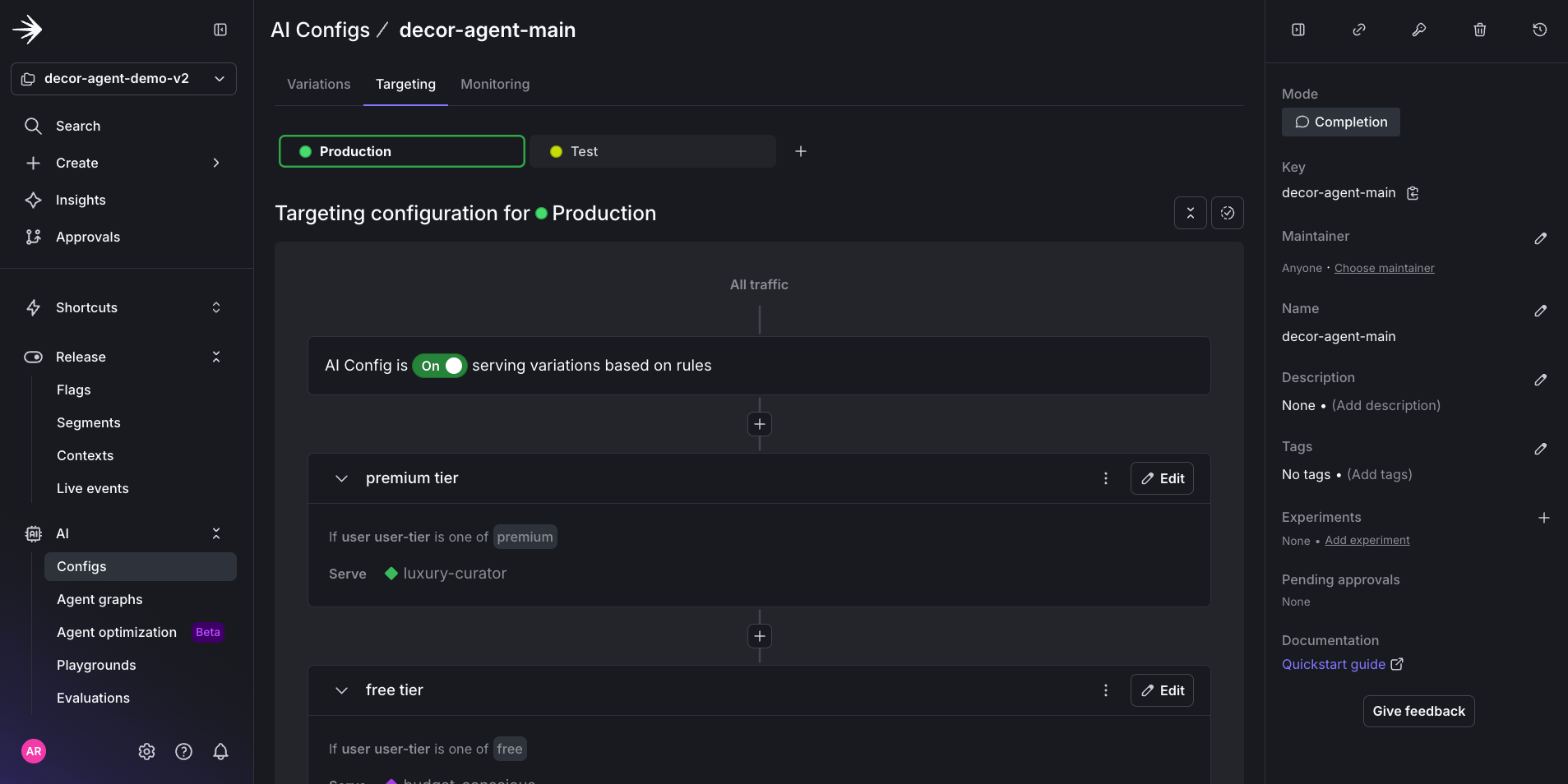
For a final test, use a toggle to change between the free and premium variations. This provokes either budget-friendly or luxury-minded responses.
Test the final result in the Decor Agent UI. Here is an example prompt:
Use the toggle to switch between the free and premium tiers and notice the difference in responses for the same prompt.
Resources
With AgentControl, a feature flag gate, targeting, and variations, we are primed for the next steps to complete this AI iteration loop, which include: