Databricks native Experimentation
Contact us for help with configuring Databricks native Experimentation
If you have both Data Export and Experimentation enabled for your LaunchDarkly account, you should have access to Databricks native Experimentation. If you do not have access or need help getting started, contact your LaunchDarkly representative or start a Support ticket.
This topic explains how to set up the Databricks native Experimentation integration. Databricks native Experimentation enables you to run experiments in LaunchDarkly using data directly from your AWS Databricks data warehouse. This lets LaunchDarkly experiments read and analyze your metrics data stored in Databricks, without requiring you to send event data through LaunchDarkly’s SDKs.
Before you can begin running Databricks native experiments, you must configure the Databricks Data Export integration in LaunchDarkly.
Prerequisites
Before setting up Databricks native Experimentation, ensure that you have:
- The Databricks Data Export integration set up in LaunchDarkly.
- Administrative access to your Databricks instance with admin permissions to access the following:
- Databricks workspace host URL
- Warehouse HTTP path
- Catalog and schema names
- Metrics database and schema names
- Personal access token (PAT) creation
- An active Databricks cluster
- A LaunchDarkly role of Owner or Admin, or a custom role that allows the following actions:
- Event data in your Databricks database that you want to use for Experimentation
- An allow list in Databricks that includes the following outbound IP addresses:
For a full list of LaunchDarkly’s public IP addresses, read Public IP list.
Step 1: Gather your Databricks cluster information
To begin, collect the server hostname and HTTP path for your Databricks cluster:
- In Databricks, navigate to SQL > SQL Warehouses.
- Select the warehouse you plan to use. This should be the same warehouse you set up for Databricks Data Export.
- Select the Connection details tab.
- Copy and save the following for use in the next section:
- Server hostname
- HTTP path
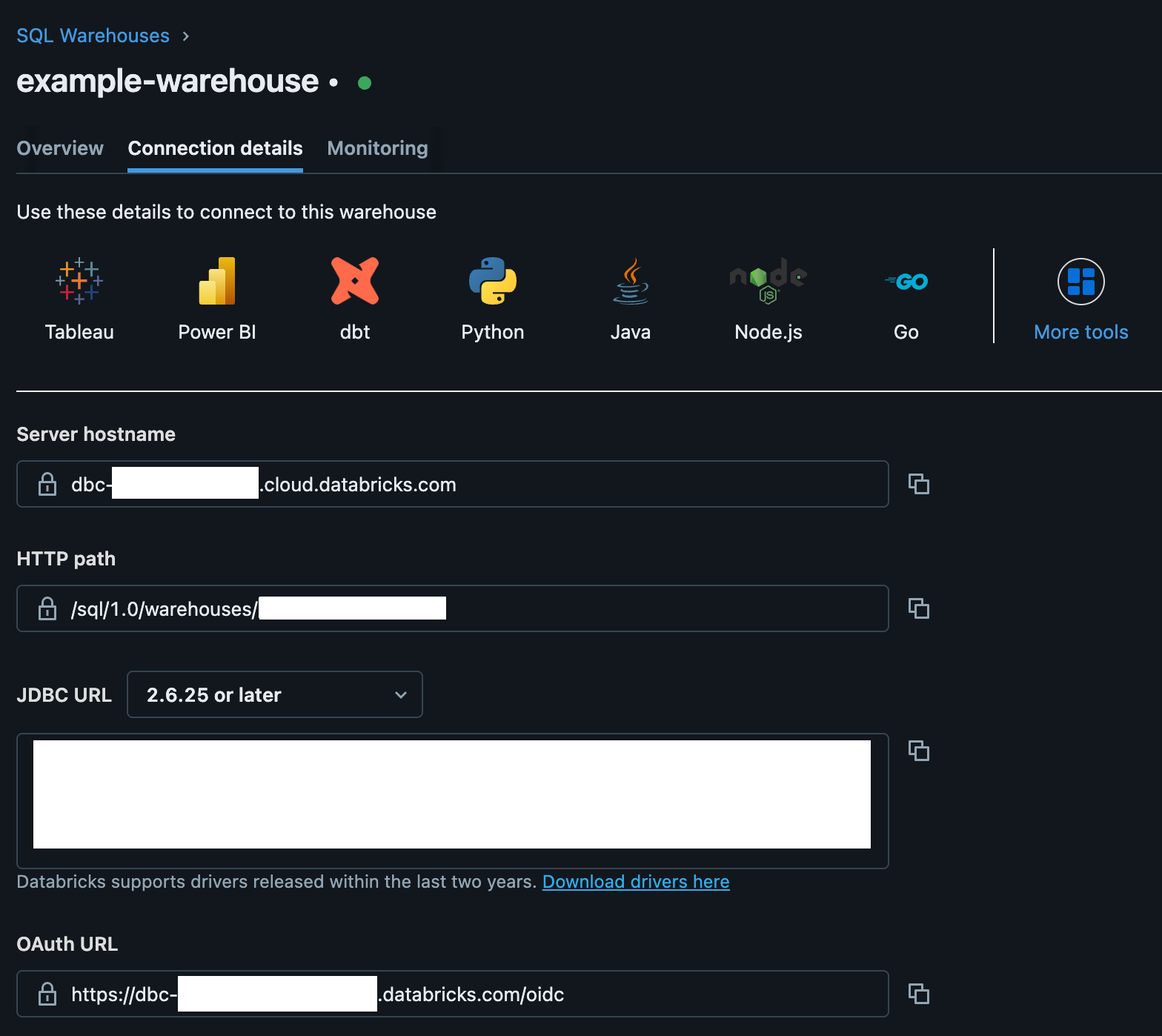
Then, collect and save the Databricks catalog name, schema name, metrics database name, and metrics schema name:
- Catalog name: The name of the Unity catalog where you will store LaunchDarkly data
- Schema name: The name of the schema where Databricks will create computed tables
- Metrics database name: The name of the database where Databricks will store metric events
- Metrics schema name: The name of the metrics schema within the Unity catalog
You will use this information in the following sections.
Step 2: In Databricks, create a PAT
To create a Databricks PAT:
- Navigate to the User tab.
- Select Workspace settings > Developer.
- Click Manage.
- Click Generate new token.
- Copy and save the PAT for use in the next section.
- Navigate to Workspace settings > Workspace admin > Advanced Personal access tokens > Permission settings.
- Enable the PAT for the workspace, and ensure that it has “can use” or “can manage” permissions.
Step 3: Configure the LaunchDarkly integration
Now, you will configure the Databricks native Experimentation integration in LaunchDarkly. This integration is a second LaunchDarkly integration that looks similar to the Databricks Data Export integration, but requires a separate setup process.
To set up the integration:
- Navigate to the Integrations page.
- Search for and select Databricks Native Experimentation.
- Click Add integration. The configuration panel appears.
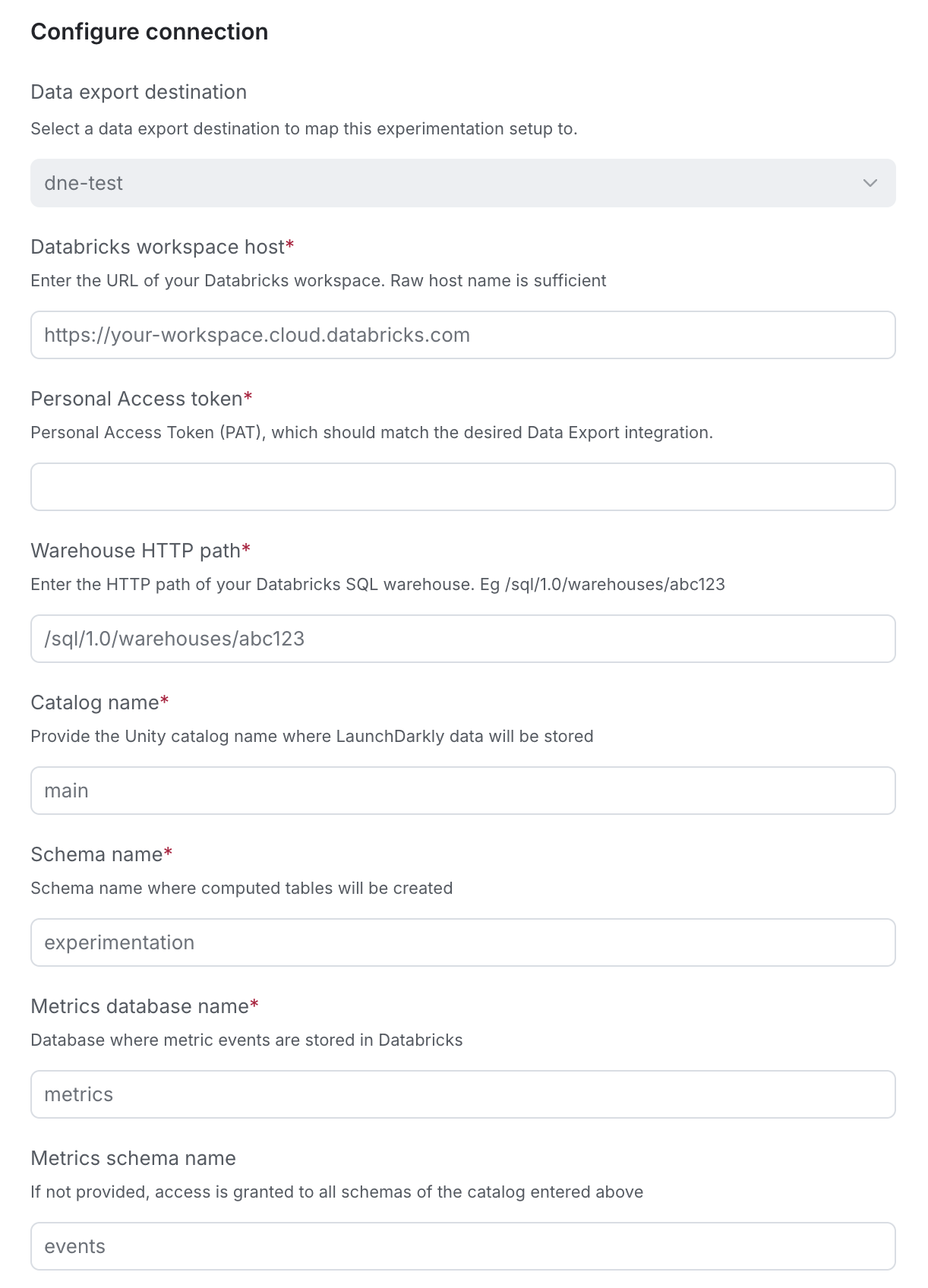
- Enter an integration Name.
- Select the LaunchDarkly Project and environment for this integration. You cannot change this after you save the integration.
- Enter the server hostname you saved from Step 1 into the Databricks workspace host field.
- Enter the PAT you saved from Step 2 into the Personal Access token field.
- Enter the HTTP path you saved from Step 1 into the Warehouse HTTP path field.
- Enter your Databricks Catalog name.
- Enter your Databricks Schema name.
- Enter your Databricks Metrics database name.
- (Optional) Enter your Databricks Metrics schema name.
- After reading the Integration Terms and Conditions, check the I have read and agree to the Integration Terms and Conditions checkbox.
- Click Save configuration.
Step 4: Verify the connection
Finally, verify the connection. On the integration configuration page, check the “Connection status” indicator. A green Healthy status confirms LaunchDarkly can connect to Databricks and has the correct permissions.
Next steps
Read the following topics to understand how to create an experiment using a Databricks native metric and how to analyze the experiment results:
The results page for a warehouse native experiment displays the date and time the results were last updated from Databricks. The initial load of experiment results can take up to 60 minutes to appear, and further results updates appear within 15–30 minutes.